[Linux] Disabling CPU turbo, cores and threads without rebooting
[Disclaimer: this has been sitting as a draft for close to three months ; I forgot to publish it, this is now finally done.]
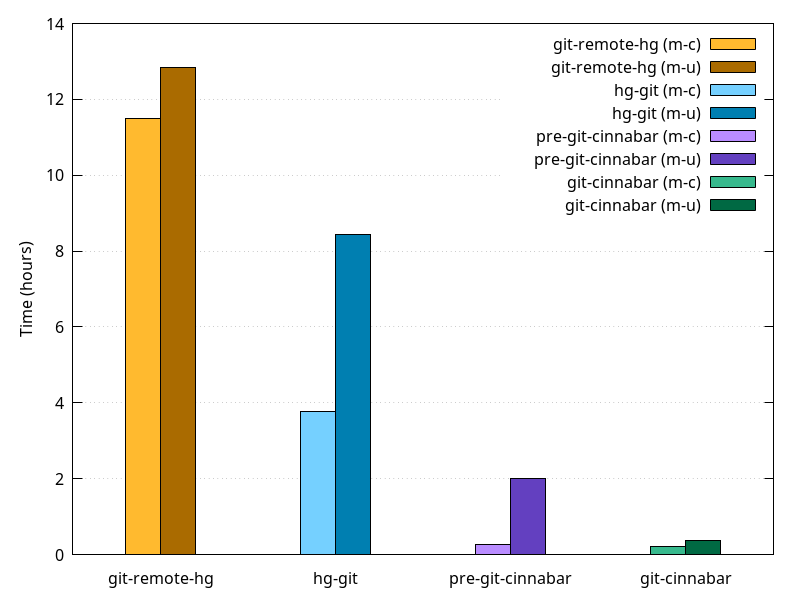
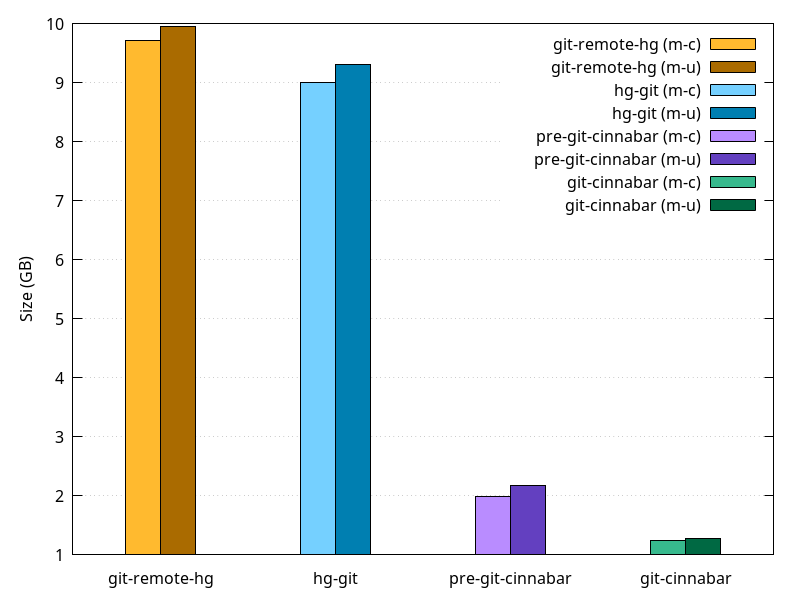
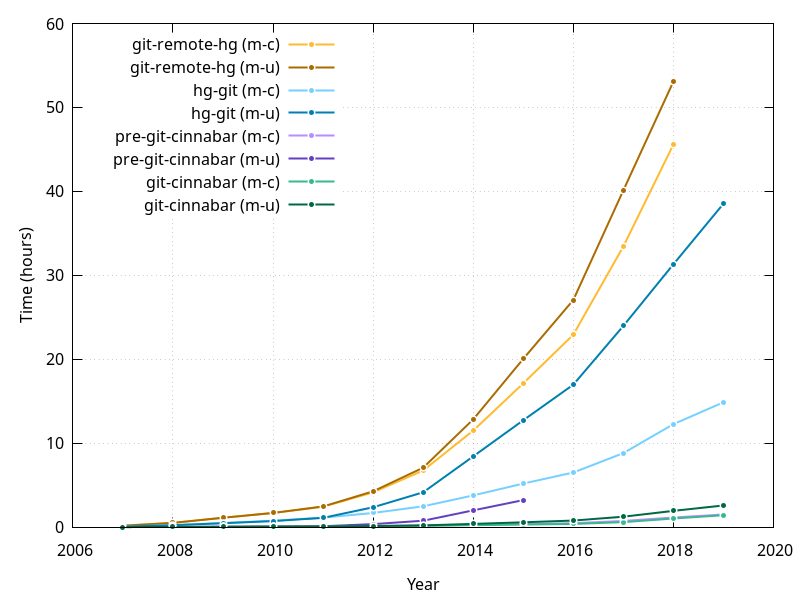
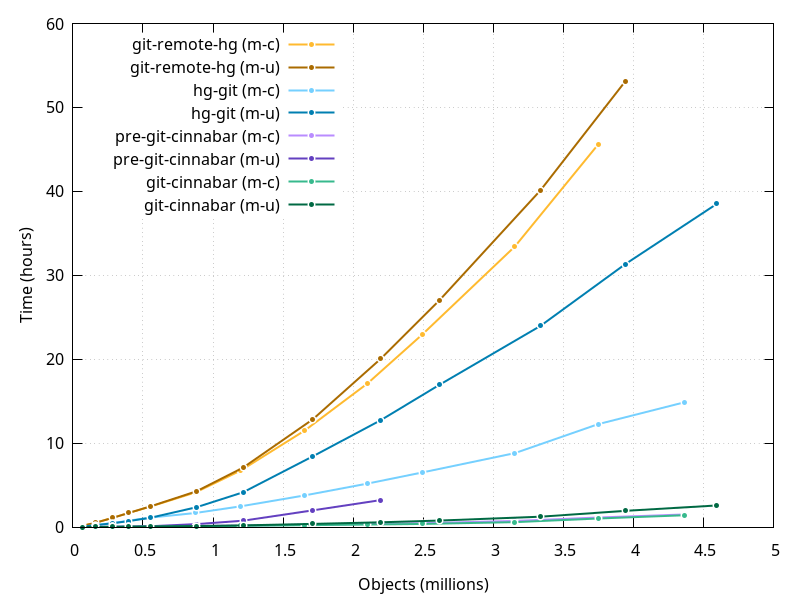
In my previous blog post, I built Firefox in a multiple different number of configurations where I'd disable the CPU turbo, some of its cores or some of its threads. That is something that was traditionally done via the BIOS, but rebooting between each attempt is not really a great experience.
Fortunately, the Linux kernel provides a large number of knobs that allow this at runtime.
Turbo
This is the most straightforward:
$ echo 0 > /sys/devices/system/cpu/cpufreq/boost
Re-enable with
$ echo 1 > /sys/devices/system/cpu/cpufreq/boost
CPU frequency throttling
Even though I haven't mentioned it, I might as well add this briefly. There are many knobs to tweak frequency throttling, but assuming your goal is to disable throttling and set the CPU frequency to its fastest non-Turbo frequency, this is how you do it:
$ echo performance > /sys/devices/system/cpu/cpu$n/cpufreq/scaling_governor
where $n is the id of the core you want to do that for, so if you want to do that for all the cores, you need to do that for cpu0, cpu1, etc.
Re-enable with:
$ echo ondemand > /sys/devices/system/cpu/cpu$n/cpufreq/scaling_governor
(assuming this was the value before you changed it ; ondemand is usually the default)
Cores and Threads
This one requires some attention, because you cannot assume anything about the CPU numbers. The first thing you want to do is to check those CPU numbers. You can do so by looking at the physical id and core id fields in /proc/cpuinfo, but the output from lscpu --extended is more convenient, and looks like the following:
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ
0 0 0 0 0:0:0:0 yes 3700.0000 2200.0000
1 0 0 1 1:1:1:0 yes 3700.0000 2200.0000
2 0 0 2 2:2:2:0 yes 3700.0000 2200.0000
3 0 0 3 3:3:3:0 yes 3700.0000 2200.0000
4 0 0 4 4:4:4:1 yes 3700.0000 2200.0000
5 0 0 5 5:5:5:1 yes 3700.0000 2200.0000
6 0 0 6 6:6:6:1 yes 3700.0000 2200.0000
7 0 0 7 7:7:7:1 yes 3700.0000 2200.0000
(...)
32 0 0 0 0:0:0:0 yes 3700.0000 2200.0000
33 0 0 1 1:1:1:0 yes 3700.0000 2200.0000
34 0 0 2 2:2:2:0 yes 3700.0000 2200.0000
35 0 0 3 3:3:3:0 yes 3700.0000 2200.0000
36 0 0 4 4:4:4:1 yes 3700.0000 2200.0000
37 0 0 5 5:5:5:1 yes 3700.0000 2200.0000
38 0 0 6 6:6:6:1 yes 3700.0000 2200.0000
39 0 0 7 7:7:7:1 yes 3700.0000 2200.0000
(...)Now, this output is actually the ideal case, where pairs of CPUs (virtual cores) on the same physical core are always n, n+32, but I've had them be pseudo-randomly spread in the past, so be careful.
To turn off a core, you want to turn off all the CPUs with the same CORE identifier. To turn off a thread (virtual core), you want to turn off one CPU. On machines with multiple sockets, you can also look at the SOCKET column.
Turning off one CPU is done with:
$ echo 0 > /sys/devices/system/cpu/cpu$n/online
Re-enable with:
$ echo 1 > /sys/devices/system/cpu/cpu$n/online
Extra: CPU sets
CPU sets are a feature of Linux's cgroups. They allow to restrict groups of processes to a set of cores.
The first step is to create a group like so:
$ mkdir /sys/fs/cgroup/cpuset/mygroupPlease note you may already have existing groups, and you may want to create subgroups. You can do so by creating subdirectories.
Then you can configure on which CPUs/cores/threads you want processes in this group to run on:
$ echo 0-7,16-23 > /sys/fs/cgroup/cpuset/mygroup/cpuset.cpusThe value you write in this file is a comma-separated list of CPU/core/thread numbers or ranges. 0-3 is the range for CPU/core/thread 0 to 3 and is thus equivalent to 0,1,2,3. The numbers correspond to /proc/cpuinfo or the output from lscpu as mentioned above.
There are also memory aspects to CPU sets, that I won't detail here (because I don't have a machine with multiple memory nodes), but you can start with:
$ cat /sys/fs/cgroup/cpuset/cpuset.mems > /sys/fs/cgroup/cpuset/mygroup/cpuset.memsNow you're ready to assign processes to this group:
$ echo $pid >> /sys/fs/cgroup/cpuset/mygroup/tasksThere are a number of tweaks you can do to this setup, I invite you to check out the cpuset(7) manual page.
Disabling a group is a little involved. First you need to move the processes to a different group:
$ while read pid; do echo $pid > /sys/fs/cgroup/cpuset/tasks; done < /sys/fs/cgroup/cpuset/mygroup/tasksThen deassociate CPU and memory nodes:
$ > /sys/fs/cgroup/cpuset/mygroup/cpuset.cpus
$ > /sys/fs/cgroup/cpuset/mygroup/cpuset.memsAnd finally remove the group:
$ rmdir /sys/fs/cgroup/cpuset/mygroup2020-08-31 07:00:38+0900