I recently upgraded my aging "fast" build machine. Back when I assembled the machine, it could do a full clobber build of Firefox in about 10 minutes. That was slightly more than 10 years ago. This upgrade, and the build times I'm getting on the brand new machine (now 6 months old) and other machines led me to look at how some parameters influence build times.
Note: most of the data that follows was gathered a few weeks ago, building off Mercurial revision 70f8ce3e2d394a8c4d08725b108003844abbbff9 of mozilla-central.
Old vs. new
The old "fast" build machine had a i7-870, with 4 cores, 8 threads running at 2.93GHz, turbo at 3.6GHz, and 16GiB RAM. The new machine has a Threadripper 3970X, with 32 cores, 64 threads running at 3.7GHz, turbo at 4.5GHz (rarely reached to be honest), and 128GiB RAM (unbuffered ECC).
Let's compare build times between them, at the same level of parallelism:
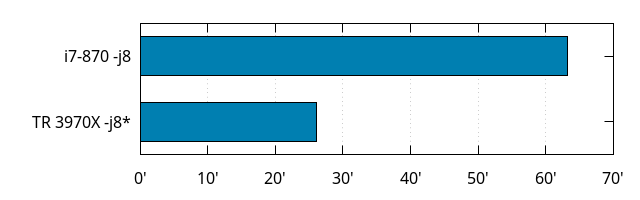
That is 63 minutes for the i7-870 vs. 26 for the Threadripper, with a twist: the Threadripper was explicitly configured to use 4 physical cores (with 2 threads each) so as to be fair to the poor i7-870.
Assuming the i7 maxed out at its base clock, and the Threadripper at turbo speed (which it actually doesn't, but it's closer to the truth than the base clock is with a eighth of the cores activated), the speed-up from the difference in frequency alone would make the build 1.5 times faster, but we got close to 2.5 times faster.
But that doesn't account for other factors we'll explore further below.
Before going there, let's look at what unleashing the full power of the Threadripper brings to the table:
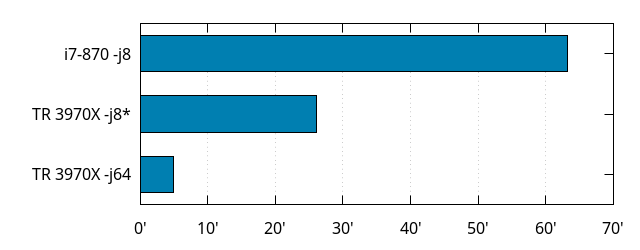
Yes, that is 5 minutes for the Threadripper 3970X, when using all its cores and threads.
Spinning disk vs. NVMe
The old machine was using spinning disks in RAID 1. I can't really test much faster SSDs on that machine because I don't have any that would fit, and the machine is now dismantled, but I was able to try the spinning disks on the Threadripper.
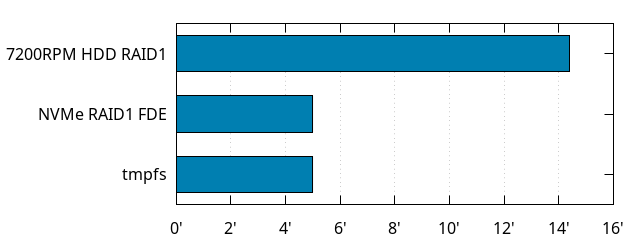
Using spinning disks instead of modern solid-state makes the build almost 3 times as slow! (or an addition of almost 10 minutes). And while I kind of went overboard with this new machine by setting up not one but two NVMe PCIe 4.0 SSDs in RAID1, I also slowed them down by using Full Disk Encryption, but it doesn't matter, because I get the same build times (within noise) if I put everything in memory (because I can).
It would be interesting to get more data with different generations of SSDs, though (SATA ones may still have a visible overhead, for instance).
Going back to the original comparison between the i7-870 and the downsized Threadripper, assuming the overhead from disk alone corresponds to what we see here (which it probably doesn't, actually, because less parallelism means less concurrent accesses, means less seeks, means more speed), the speed difference now looks closer to "only" 2x.
Desktop vs. Laptop
My most recent laptop is a 3.5 years old Dell XPS13 9360, that came with a i7-7500U (2 cores, 4 threads, because that's all you could get in the 13" form factor back then; 2.7GHz, 3.5GHz turbo), and 16GiB RAM.
A more recent 13" laptop would be the Apple Macbook Pro 13" Mid 2019, sporting an i7-8569U (4 cores, 8 threads, 2.8GHz, 4.7GHz turbo), and 16GiB RAM. I don't own one, but Mozilla's procurement system contains build times for it (although I don't know what changeset that corresponds to, or what compilers were used ; also, the OS is different).
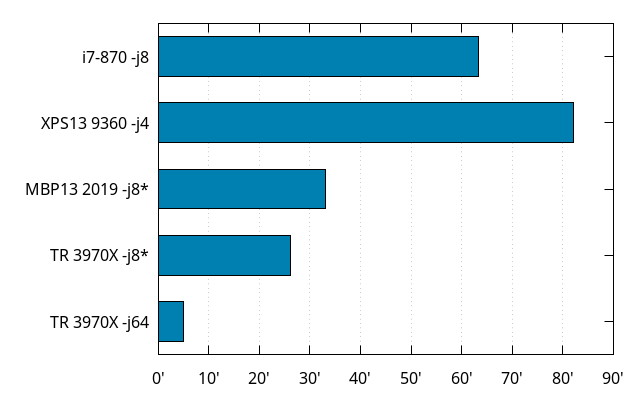
The XPS13 being old, it is subject to thermal throttling, making it slower than it should be, but it wouldn't beat the 10 years old desktop anyway. Macbook Pros tend to get into these thermal issues after a while too.
I've relied on laptops for a long time. My previous laptop before this XPS was another XPS, that is now about 6 to 7 years old, and while the newer one had more RAM, it was barely getting better build times compared to the older one when I switched. The evolution of laptop performance has been underwelming for a long time, but things finally changed last year. At long last.
I wish I had numbers with a more recent laptop under the same OS as the XPS for fairer comparison. Or with the more recent larger laptops that sport even more cores, especially the fancy ones with Ryzen processors.
Local vs. Cloud
As seen above, my laptop was not really a great experience. Neither was my faster machine. When I needed power, I actually turned to AWS EC2. That's not exactly cheap for long term use, but I only used it for a couple hours at a time, in relatively rare occasions.
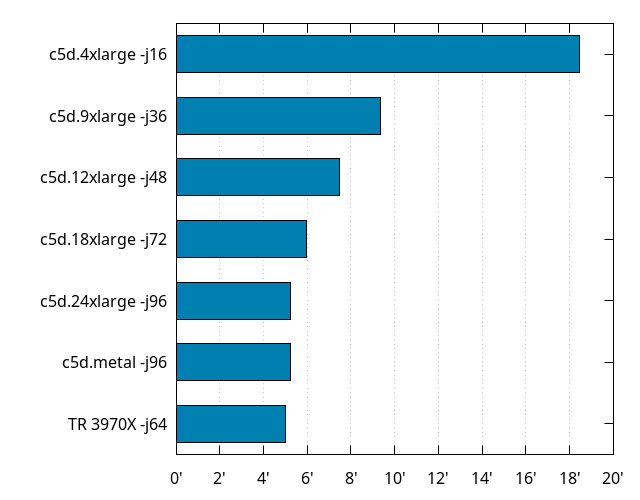
The c5d instances are AFAIK, and as of writing, the most powerful you can get on EC2 CPU-wise. They are based on 3.0GHz Xeon Platinum CPUs, either 8124M or 8275CL (which don't exist on Intel's website. Edit: apparently, at least the 8275CL can turbo up to 3.9GHz). The 8124M is Skylake-based and the 8275CL is Cascade Lake, which I guess is the best you could get from Intel at the moment. I'm not sure if it's a lottery of some sort between 8124M and 8275CL, or if it's based on instance type, but the 4xlarge, 9xlarge and 18xlarge were 8124M and 12xlarge, 24xlarge and metal were 8275CL. Skylake or Cascade Lake doesn't seem to make much difference here, but that would need to be validated on a non-virtualized environment with full control over the number of cores and threads being used.
Speaking of virtualization, one might wonder what kind of overhead it has, and as far as building Firefox goes, the difference between c5d.metal (without) and c5d.24xlarge (with), is well within noise.
As seen earlier, storage can have an influence on build times, and EC2 instances can use either EBS storage or NVMe. On the c5d instances, it made virtually no difference. I even compared with everything in RAM (on instances with enough of it), and that didn't make a difference either. Take this with a grain of salt, though, because EBS can be slower on other types of instances. Also, I didn't test NVMe or RAM on c5d.4xlarge, and those have slower networking so there could be a difference there.
There are EPYC-based m5a instances, but they are not Zen 2 and have lower frequencies, so they're not all that good. Who knows when Amazon will deliver their Zen 2 offerings.
Number of cores
The Firefox build system is not perfect, and the number of jobs it's allowed to run at once can have an influence on the overall build times, even on the same machine. This can somehow be observed on the results on AWS above, but testing different values of -jn on a machine with a large number of cores is another way to investigate how well the build system scales. Here it is, on the Threadripper 3970X:
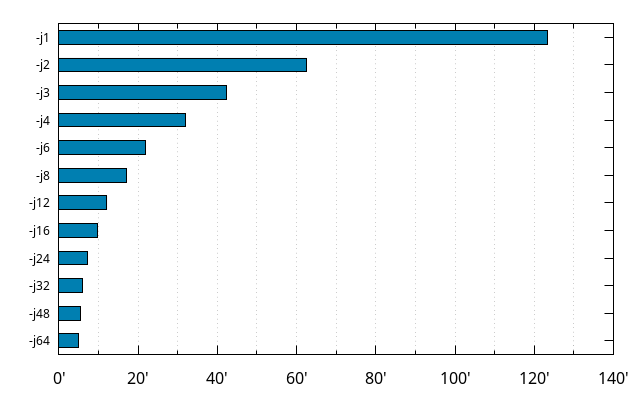
Let's pause a moment to appreciate that this machine can build slightly faster, with only 2 cores, than the old machine could with 4 cores and 8 threads.
You may also notice that the build times at -j6 and -j8 are better than the -j8 build time given earlier. More on that further below.
The data, however, is somehow skewed as far as getting a clear picture of how well the Firefox build system scales, because the less cores and threads are being used, the faster those cores can get, thanks to "Turbo". As mentioned earlier, the base frequency for the processor is 3.7GHz, but it can go up to 4.5GHz. In practice, /proc/cpuinfo doesn't show much more than 4.45GHz when few cores are used, but on the opposite end, would frequently show 3.8GHz when all of them are used. Which means all the values in that last graph are not entirely comparable to each other.
So let's see how things go with Turbo disabled (note, though, that I didn't disable dynamic CPU frequency scaling):
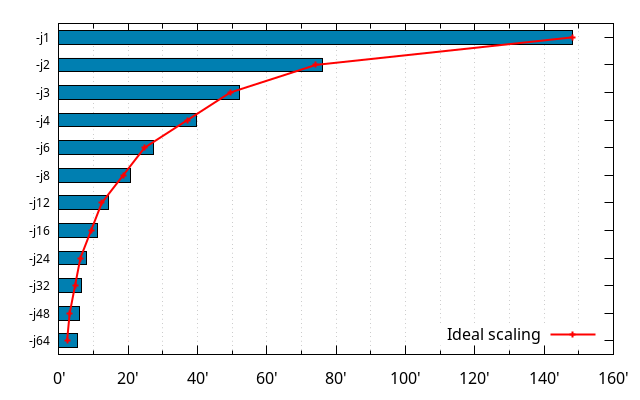
The ideal scaling (red line) is the build time at -j1 divided by the n in -jn.
So, at the scale of the graph above, things look like there's some kind of constant overhead (the parts of the build that aren't parallelized all that well), and a part that is within what you'd expect for parallelization, except above -j32 (we'll get to that last part further down).
Based on the above, let's assume a modeled build time of the form O + P / n. We can find some O and P that makes the values for e.g. -j1 and -j32 correct. That works out to be 1.9534 + 146.294 / n (or, in time format: 1:57.2 + 2:26:17.64 / n).
Let's see how it fares:
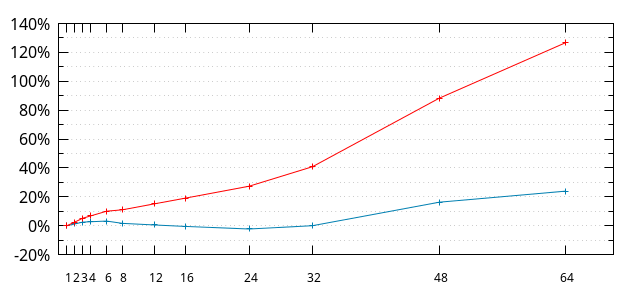
The red line is how far from the ideal case (-j1/n) the actual data is, in percent from the ideal case. At -j32, the build time is slightly more than 1.4 times what it ideally would be. At -j24, about 1.3 times, etc.
The blue line is how far from the modeled case the actual data is, in percent from the modeled case. The model is within 3% of reality (without Turbo) until -j32.
And above -j32, things blow up. And the reason is obvious: the CPU only has 32 actual cores. Which brings us to...
Simultaneous Multithreading (aka Hyperthreading)
Ever since the Pentium 4, many (and now most) modern desktop and laptop processors have had some sort of Simultaneous Multithreading (SMT) technology. The underlying principle is that CPUs are waiting for something a lot of the time (usually data in RAM), and that they could actually be executing something else when that happens.
From the software perspective, though, it only appears to be more cores than there physically are. So on a processor with 2 threads per core like the Threadripper 3970X, that means the OS exposes 64 "virtual" cores instead of the 32 physical ones.
When the workload doesn't require all the "virtual" cores, the OS will schedule code to run on virtual cores that don't share the same physical core, so as to get the best of one's machine.
This is why -jn on a machine that has n real cores or more will have better build times than -jn on a machine with less cores, but at least n virtual cores.
This was already exposed in some way above, where the first -j8 build time shown was worse than the subsequent ones. That one was taken while disabling all physical cores but 4, and still keeping 2 threads per core. Let's compare that with similar number of real cores:
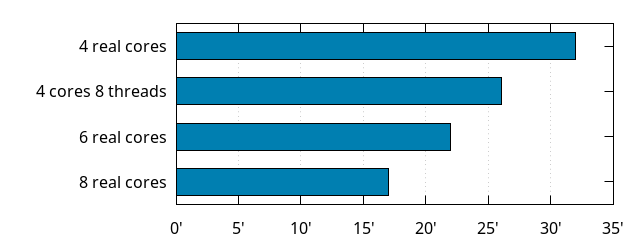
As we can see, 4 cores with 8 threads is better than 4 cores, but it doesn't beat 6 physical cores. Which kind of matches the general wisdom that SMT brings an extra 30% performance.
By the way, this being all on a Zen 2 processor, I'd expect a Ryzen 3 3300X to provide similar build times to that 4 cores 8 threads case.
Let's look at 16 cores and 32 threads:
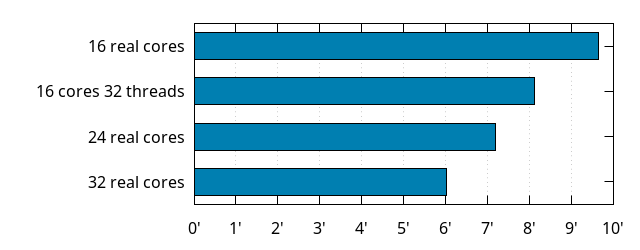
Similar observation: obviously better than 16 cores alone, but worse than 24 physical cores. And again, this being all on a Zen 2 processor, I'd expect a Ryzen 9 3950X to provide similar build times to the 16 cores and 32 threads case.
Based on the above, I'd estimate a Threadripper 3960X to have build times close to those of 32 real cores on the 3970X (32 cores is 33% more cores than 24).
Operating System
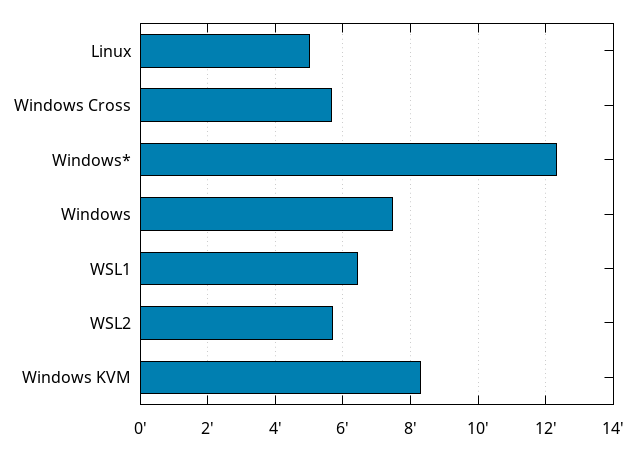
All the build times mentioned above except for the Macbook Pro have been taken under Debian GNU/Linux 10, building Firefox for Linux64 from a specific revision of mozilla-central without any tweaks.
Things get different if you build for a different target (say, Firefox for Windows), or under a different operating system.
Our baseline on this machine is the Firefox for Linux64 build is 5 minutes. Building Firefox for Windows (as a cross-compilation) takes 40 more seconds (5:40), because of building some extra Windows-specific stuff.
A similar Firefox for Windows build, natively, on a fresh Windows 10 install takes ... more than 12 minutes! Until you realize you can disable Windows Defender for the source and build tree, at which point it only takes 7:27. That's still noticeably slower than cross-compiling, but not as catastrophic as when the antivirus is enabled.
Recent versions of Windows come with a Windows Subsystem for Linux (WSL), which allows to run native Linux programs unmodified. There are now actually two versions of WSL. One emulates Linux system calls (WSL1), and the other runs a real Linux kernel in a virtual machine (WSL2). With a Debian GNU/Linux 10 system under WSL1, building Firefox for Linux64 takes 6:25, while it takes 5:41 under WSL2, so WSL2 is definitely faster, but still not close to metal.
Edit: Ironically, it's very much possible that a cross-compiled Firefox for Windows build in WSL2 would be faster than a native Firefox for Windows build on Windows (but I haven't tried).
Finally, a Firefox for Windows build, on a fresh Windows 10 install in a KVM virtual machine under the original Debian GNU/Linux system takes 8:17, which is a lot of overhead. Maybe there are some tweaks to do to get better build times, but it's probably better to go with cross-compilation.
Let's recap as a graph:
Automation
All the build times mentioned so far have been building off mozilla-central without any tweaks. That's actually not how a real Firefox release is built, which enables more optimizations. Without even going to the full set of optimizations that go into building a real Firefox Nightly (including Link Time Optimizations and Profile Guided Optimizations), simply switching --enable-release on will up the optimization game.
Building on Mozilla automation also enables things that don't happen during what we call "local developer builds", such as dumping debug info for use to process crash reports, linking a second libxul library for some unit tests, the full packaging of Firefox, the preparation of archives that will be used to run tests, etc.
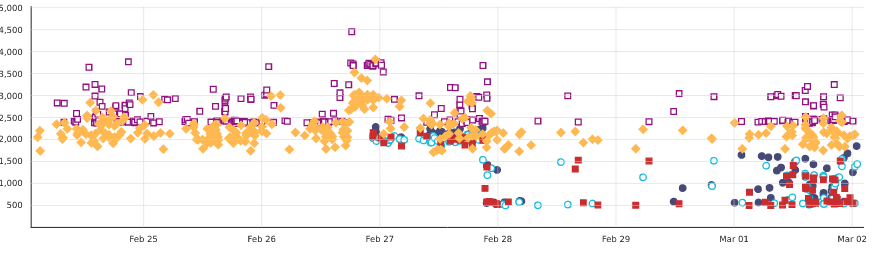
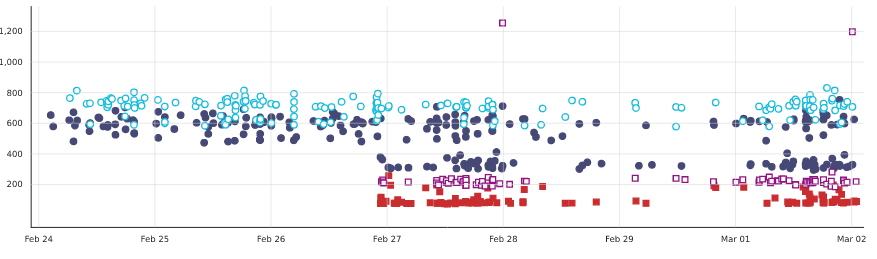
As of writing, most Firefox builds on Mozilla automation happen on c5d.4xlarge (or similarly sized) AWS EC2 instances. They benefit from the use of a shared compilation cache, so their build times are very noisy, as they depend on the cache hit rate.
So, I took some Linux64 optimized build that runs on automation (not one with LTO or PGO), and ran its full script, with the shared compilation cache disabled, on corresponding and larger AWS EC2 instances, as well as the Threadripper:
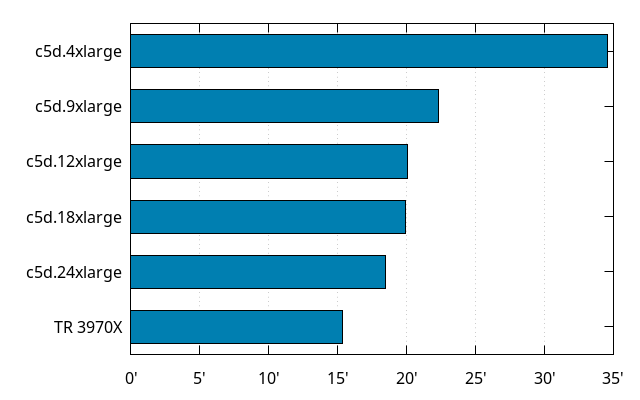
The immediate observation is that these builds scale much less gracefully than a "local developer build" does, and there are multiple factors that come into play, but the common thread is that parts of the build that don't run during those "local developer builds" are slow and not well parallelized. Work is in progress to make things better, though.
Another large contributor is that with the higher level of optimizations, the compilation of Rust code takes longer. And compiling Rust doesn't parallelize very well at the moment (for a variety of reasons, but the main one is the long sequences of crate dependencies, i.e. when A depends on B, which depends on C, which depends on D, etc.). So what happens the more cores are available, is that compiling all the C/C++ code finishes well before compiling all the Rust code does, and with the long tail of crate dependencies, what's remaining doesn't parallelize well. And that also blocks other portions of the build that need the compiled Rust code, and aren't very well parallelized themselves.
All in all, it's not all that great to go with bigger instances, because they cost more but won't compensate by doing as many more builds in the same amount of time... except if doing more builds in parallel, which is being experimented with.
On the Threadripper 3970X, I can do 2 "local developer builds" in parallel in less time than doing them one after the other (1:20 less, so 8:40 instead of 10 minutes). Even with -j64. Heck, I can do 4 builds in parallel at -j16 in 16 minutes and 15 seconds, which is somewhere between a single -j12 and single -j8, which is where one -j16 with 8 threads and 16 threads should be at. That doesn't seem all that useful, until you think of it this way: I can locally build for multiple platforms at once in well under 20 minutes. All on one machine, from one source tree.
Closing words
We looked at various ways build times can vary depending on different hardware (and even software) configurations. Note this only covers hardware parameters that didn't require reboots to test out (e.g. this excludes variations like RAM speed ; and yes, this means there are ways to disable turbo, cores and threads without fiddling with the BIOS, I'll probably write a separate blog post about this).
We saw there is room for improvements in Firefox build times, especially on automation. But even for local builds, on machines like mine, it should be possible to get under 4 minutes eventually. Without any form of caching. Which is kind of mind blowing. Even without these future improvements, these build times changed the way I approach things. I don't mind clobber builds anymore, although ideally we'd never need them.
If you're on the market for a new machine, I'd advise getting a powerful desktop machine (based on a 3950X, a 3960X or a 3970X) rather than refreshing your aging laptop. I don't think any laptop currently available would get below 15 minutes build times. And those that can build in less than 20 minutes probably cost more than a desktop machine that would build in well under half that. Edit: Also, pick a fast NVMe SSD that can sustain tons of IOPS.
Of course, if you use some caching method, build times will be much better even on a slower machine, but even with a cache, it happens quite often that you get a lot of cache misses that cancel out the benefit of the cache. YMMV.
You may also have legitimate concerns that rr doesn't work yet, but when I need it, I can pull my old Intel-based laptop. rr actually works well enough on Ryzen for single-threaded workloads, and I haven't needed to debug Firefox itself with rr recently, so I haven't actually pulled the old laptop a lot (although I have been using rr and Pernosco).