Five years of git-cinnabar
On this very day five years ago, I committed the initial code of what later became git-cinnabar. It is kind of an artificial anniversary, because I didn't actually publish anything until 3 weeks later, and I also had some prototypes months earlier.
The earlier prototypes of what I'll call "pre-git-cinnabar" could handle doing git clone hg::https://hg.mozilla.org/mozilla-central (that is, creating a git clone of a Mercurial repository), but they couldn't git pull later. That pre-git-cinnabar initial commit, however, was the first version that did.
The state of the art back then was similar git helpers, the most popular choice being Felipec's git-remote-hg, or the opposite tool: hg-git, a mercurial plugin that allows to push to a git repository.
They both had the same caveats: they were slow to handle a repository the size of mozilla-central back then, and both required a local mercurial repository (hidden in the .git directory in the case of Felipec's git-remote-hg).
This is what motivated me to work on pre-git-cinnabar, which was also named git-remote-hg back then because of how git requires a git-remote-hg executable to handle hg::-prefixed urls.
Fast forward five years, mozilla-central has grown tremendously, and another mozilla-unified repository was created that aggregates the various mozilla branches (esr*, release, beta, central, integration/*).
git-cinnabar went through multiple versions, multiple changes to the metadata it keeps, and while I actually haven't cumulatively worked all that much on it considering the number of years, a lot of progress has been made.
But let's go back to the 19th of November 2014. Thankfully, Mercurial allows to strip everything past a certain date, artificially allowing to restore the state of the repository at that date. Unfortunately, pre-git-cinnabar only supports the old Mercurial bundle format, which both the mozilla-central and mozilla-unified repositories now don't allow. So pre-git-cinnabar can't clone them out of the box anymore. It's still possible to allow it in mirror repositories, but because they now use generaldelta, that incurs a server-side conversion that is painfully slow (the hg.mozilla.org server rejects clients that don't support the new format for this reason).
So for testing purposes, I setup a nginx reverse-proxy and cache, such that the conversion only happens once, and performed clones multiple times, removing any bundling and conversion cost out of the equation. And tested the current version of Felipec's git-remote-hg, the current version of hg-git, pre-git-cinnabar, and last git-cinnabar release (0.5.2 as of writing), on some AWS instances, with Xeon Platinum 8124M 3Ghz CPUs. That's a different CPU from what I had back in 2014, yielding some different results from what I wrote in that first announcement.
I've thus cloned both mozilla-central (denoted m-c) and mozilla-unified (denoted m-u), with simulated old states of the repositories. Mozilla-unified didn't exist before 2016, but it's still interesting to simulate its content as if it had existed because it allows to learn how the tools perform with the additional branches it contains, with the implication they have on how the data is stored in the repository.
Note: I didn't test older versions of git-remote-hg or hg-git to see how they performed at the time, and how things evolved for them.
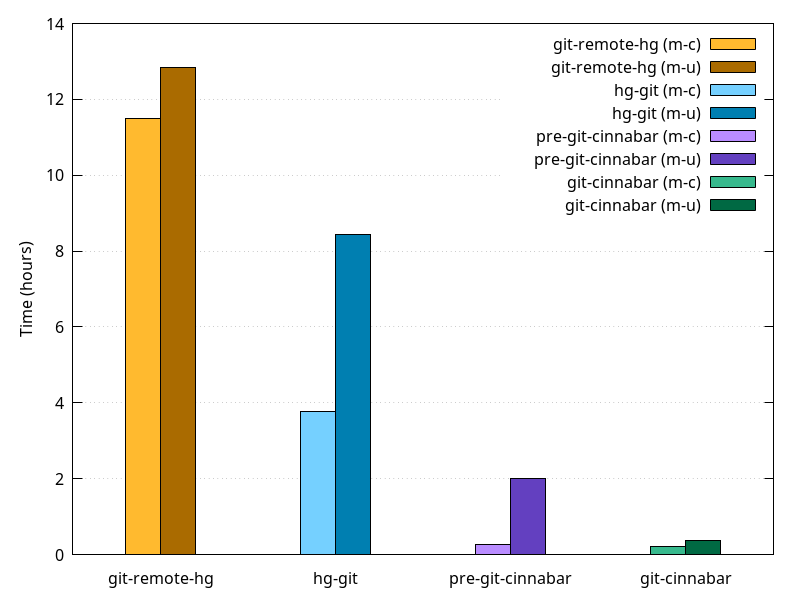
There are multiple things of note in the results above:
- I wrote back then that cloning took 12 hours with git-remote-hg and 30 minutes with pre-git-cinnabar on the machine I used. And while cloning with pre-git-cinnabar on more modern hardware was much faster (16 minutes), cloning with git-remote-hg wasn't. The pre-git-cinnabar improvement could, though, be attributed in part to improvements in
git-fast-importitself (I haven't tested older versions). But it's also not impossible that git-remote-hg regressed. Only further testing would tell. - mozilla-unified is bigger than mozilla-central, because it is a superset, and that reflects on the clone times, but hg-git and pre-git-cinnabar are both much slower to clone mozilla-unified than you'd expect from the difference in size, especially hg-git. git-cinnabar made a lot of progress in that regard.
- I hadn't tested hg-git back then, but while it's not as slow as git-remote-hg, it's still horribly slow for a repository this size.
Let's now look at the .git sizes:
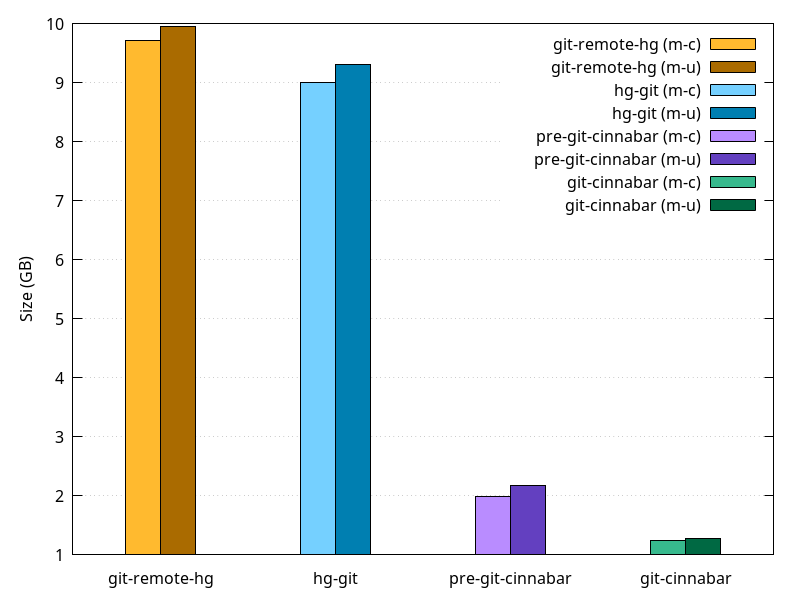
Those are the sizes for the .git directory fresh after cloning. In all cases, git gc --aggressive would make the clone smaller, at the cost of CPU time (although not significantly smaller in the git-cinnabar case). And after you spent 12 hours cloning, are you really going to spend another large number of hours on a git gc to save disk space?
It is worth noting that in the case of hg-git, this doesn't include the size of the mercurial repository required to maintain the git repository, while it is included for git-remote-hg, where it is hidden in .git, as mentioned earlier. That puts them about on par w.r.t size.
It's interesting how close hg-git and git-remote-hg are in disk usage, when the former uses dulwich, a pure Python implementation of Git, and the latter uses git-fast-import. pre-git-cinnabar used git-fast-import too, but optimized the data it sent to git-fast-import to allow for a more compact .git. Recent git-cinnabar made it even better, although it doesn't use git-fast-import directly, instead using a helper derived
from git-fast-import.
But that was 2014. Let's look at how things evolved over time, by taking "snapshots" of the repositories at one year interval, starting in November 2007.
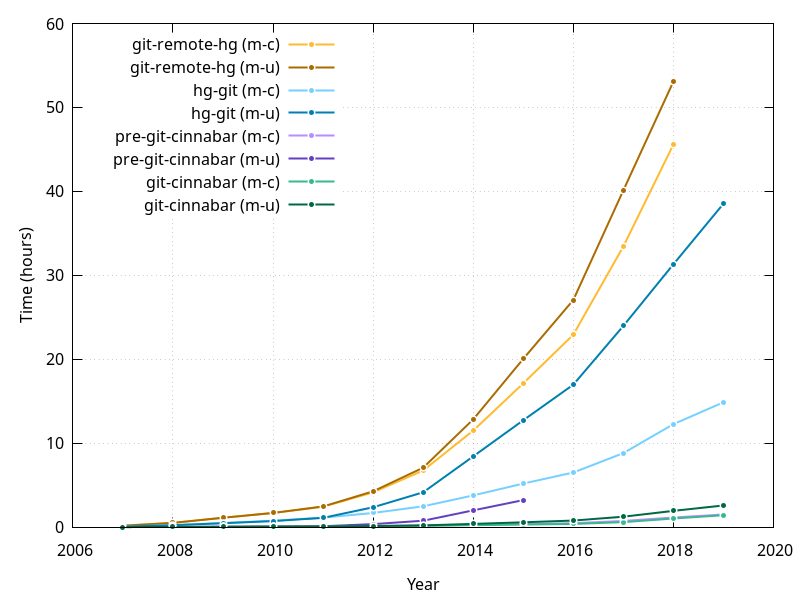
Of note:
- pre-git-cinnabar somehow invalidated the nginx cache for years >= 2016 for mozilla-unified, which didn't allow to get reliable measures.
- Things went well out of hand with git-remote-hg and hg-git, so much so that I wasn't able to get results for git-remote-hg clones for 2019 in time for this post. They're now getting clone times that count in days rather than hours.
- Things are getting much worse with mozilla-unified, relatively to mozilla-central, for hg-git than they do for git-remote-hg or git-cinnabar, while they were really bad with pre-git-cinnabar.
- pre-git-cinnabar clone times for mozilla-central are indistinguishable from git-cinnabar's at this scale (but see further below).
- the progression is not linear, but the progression in repository size wasn't linear either. In order to get a slightly better picture, it is better to look at the clone times vs. the size of the repositories. One measure of that size is number of objects (changeset, manifests and file revisions they contain).
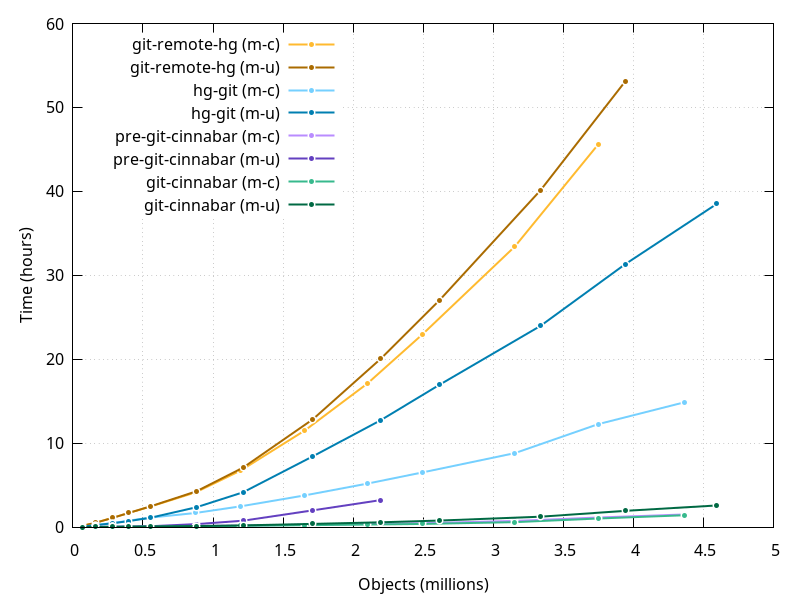
The progression here looks more linear, but still not quite linear. The difference between the mozilla-central and mozilla-unified clone times is the most damning, especially for hg-git and pre-git-cinnabar. At this scale things don't look so bad for git-cinnabar, but looking closer, they aren't actually much better:
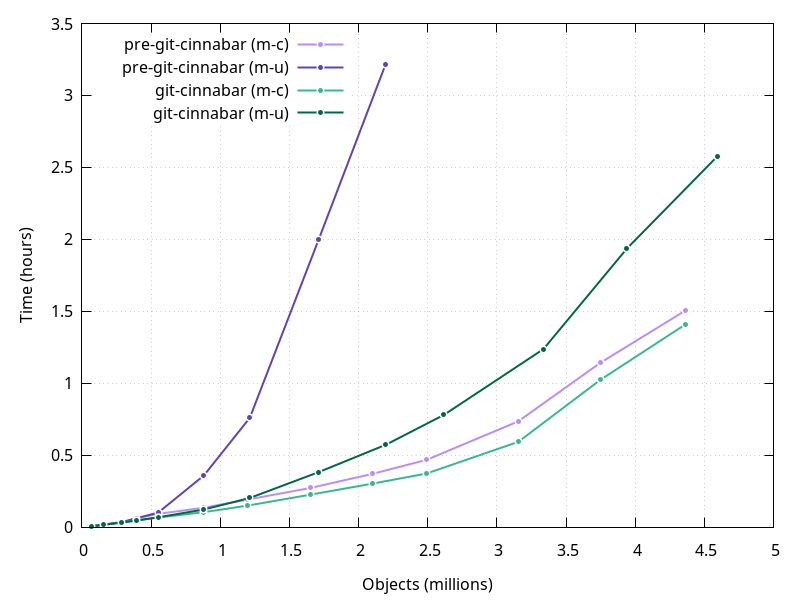
mozilla-central clone times have slightly improved since pre-git-cinnabar days, at least more than the comparison with hg-git and git-remote-hg suggested. mozilla-unified clone times, however, have dramatically improved (notwithstanding the fact that it's currently not possible to clone with pre-git-cinnabar at all directly from hg.mozilla.org).
But clone times are starting to get a little out of hand, especially for mozilla-unified, which is why I've recently added support for "clone bundles". But I also have work in progress that I expect will make non-bundle clones faster too, and hopefully more linear.
As for .git sizes:
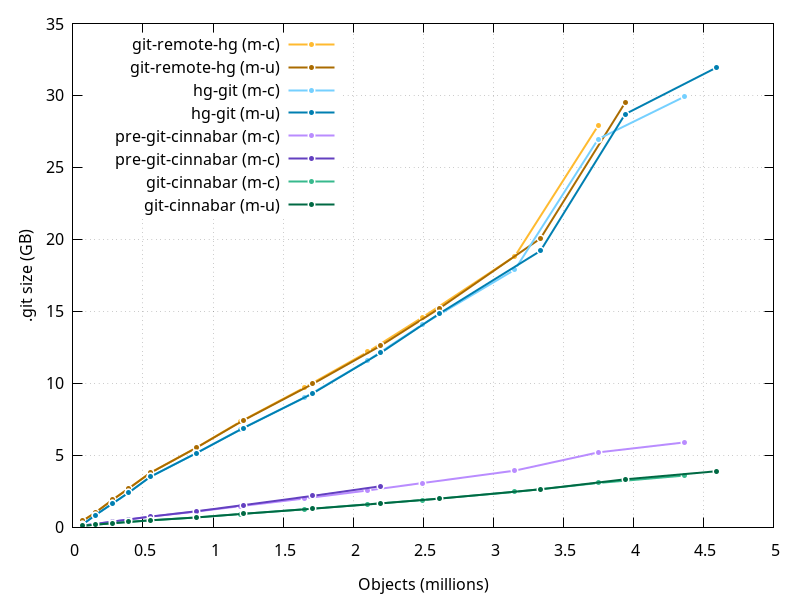
- hg-git and git-remote-hg are still hand in hand.
- Here the progression is mostly linear, with almost no difference between mozilla-central and mozilla-unified, as one could expect.
- I think the larger increase in size between what would be 2017 and 2018 is largely due to the
testing/web-platform/meta/MANIFEST.jsonfile. - People who try to clone the Mozilla repositories with hg-git or git-remote-hg at this point better have a lot of time and a lot of free disk space.
While git-cinnabar is demonstrably significantly faster than both git-remote-hg and hg-git by a large margin for the Mozilla repositories (more than an order of magnitude), looking at the data more closely revealed something interesting that can be pictured in the following graph, plotting how much slower than git-cinnabar the other tools are.
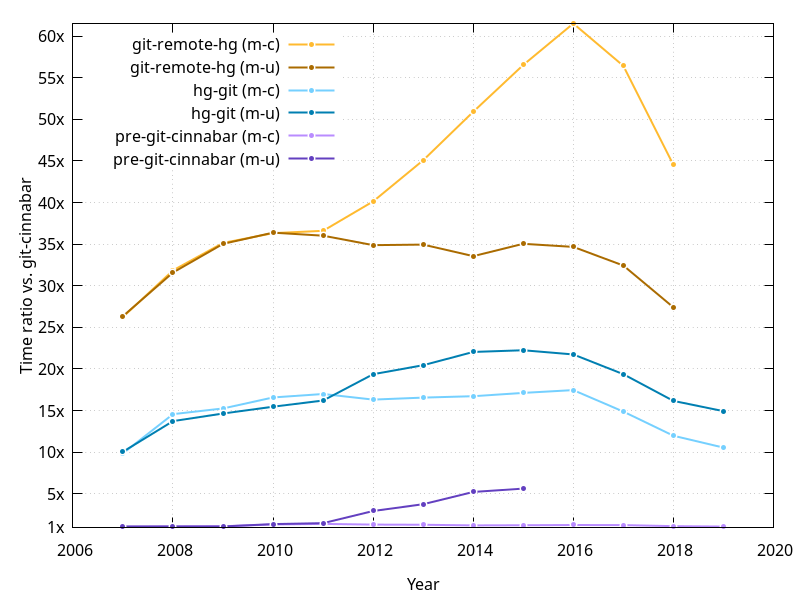
The ratio is not constant, and has surprisingly been decreasing steadily since 2016, correlating with the observation that clone times are getting slower more quickly than the repositories are growing. But they are doing more so with git-cinnabar than with the other tools. Clone times with git-cinnabar have multiplied by more than 5 in five years, for a repository that only has 2.5 times more objects. At this pace, in five more years, clones will take well above 10 hours, and that's not counting for the accelerated slowdown. Hopefully, the current work in progress will help.
It's also interesting to see how the ratios changed after 2011 between mozilla-central and mozilla-unified. 2011 is when Firefox 4 was released and the release process switched to multiple repositories, which mozilla-unified, well, unified in a single repository. So mozilla-unified and mozilla-central were largely identical when stripped of commits after 2011 and started diverging afterwards.
To conclude this rather long post, pre-git-cinnabar improved the state of the art to clone large Mercurial repositories, and git-cinnabar went further in the past five years. But without more work, things will get out of hand. And that only accounts for clone times. I haven't spent much time working on other aspects, like negotiation times (the time it takes to agree with a Mercurial server what the git clone has in common with it), or bundling times (the time it takes to generate a bundle to send a Mercurial server). Both are the relevant parts of push times.
2019-11-19 18:04:26+0900
