Analyzing git-cinnabar memory use
In previous post, I was looking at the allocations git-cinnabar makes. While I had the data, I figured I'd also look how the memory use correlates with expectations based on repository data, to put things in perspective.
As a reminder, this is what the allocations look like (horizontal axis being the number of allocator function calls):
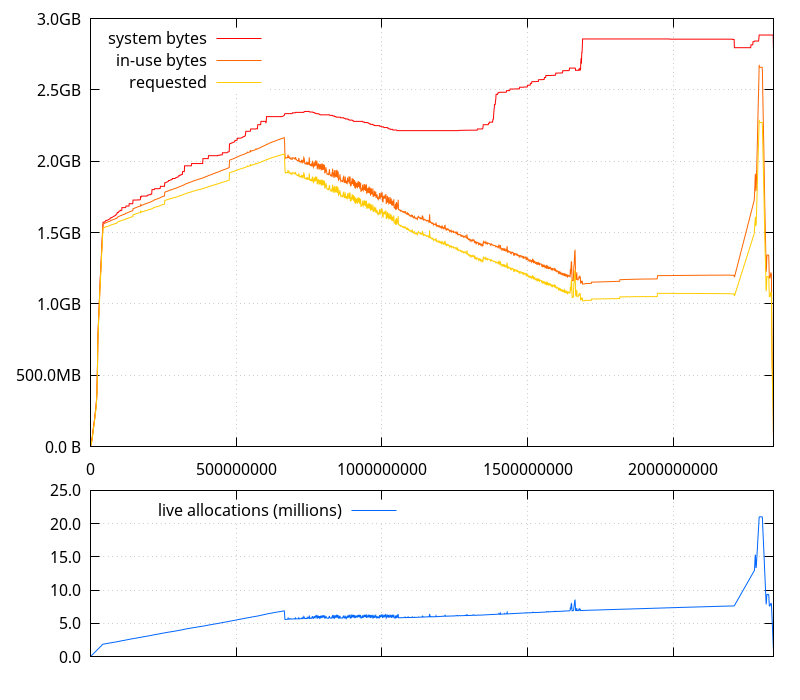
There are 7 different phases happening during a git clone using git-cinnabar, most of which can easily be identified on the graph above:
- Negotiation.
During this phase, git-cinnabar talks to the mercurial server to determine what needs to be pulled. Once that is done, a
getbundlerequest is emitted, which response is read in the next three phases. This phase is essentially invisible on the graph. - Reading changeset data.
The first thing that a mercurial server sends in the response for a
getbundlerequest is changesets. They are sent in the RevChunk format. Translated to git, they become commit objects. But to create commit objects, we need the entire corresponding trees and files (blobs), which we don't have yet. So we keep this data in memory.In the
git cloneanalyzed here, there are 345643 changesets loaded in memory. Their raw size in RawChunk format is 237MB. I think by the end of this phase, we made 20 million allocator calls, have about 300MB of live data in about 840k allocations. (No certainty because I don't actually have definite data that would allow to correlate between the phases and allocator calls, and the memory usage change between this phase and next is not as clear-cut as with other phases). This puts us at less than 3 live allocations per changeset, with "only" about 60MB overhead over the raw data. - Reading manifest data.
In the stream we receive, manifests follow changesets. Each changeset points to one manifest ; several changesets can point to the same manifest. Manifests describe the content of the entire source code tree in a similar manner as git trees, except they are flat (there's one manifest for the entire tree, where git trees would reference other git trees for sub directories). And like git trees, they only map file paths to file SHA1s. The way they are currently stored by git-cinnabar (which is planned to change) requires knowing the corresponding git SHA1s for those files, and we haven't got those yet, so again, we keep everything in memory.
In the
git cloneanalyzed here, there are 345398 manifests loaded in memory. Their raw size in RawChunk format is 1.18GB. By the end of this phase, we made 23 million more allocator calls, and have about 1.52GB of live data in about 1.86M allocations. We're still at less than 3 live allocations for each object (changeset or manifest) we're keeping in memory, and barely over 100MB of overhead over the raw data, which, on average puts the overhead at 150 bytes per object.The three phases so far are relatively fast and account for a small part of the overall process, so they don't appear clear-cut to each other, and don't take much space on the graph.
- Reading and Importing files.
After the manifests, we finally get files data, grouped by path, such that we get all the file revisions of e.g.
.cargo/.gitignore, followed by all the file revisions of.cargo/config.in,.clang-format, and so on. The data here doesn't depend on anything else, so we can finally directly import the data.This means that for each revision, we actually expand the RawChunk into the full file data (RawChunks contain patches against a previous revision), and don't keep the RawChunk around. We also don't keep the full data after it was sent to the
git-cinnabar-helperprocess (as far as cloning is concerned, it's essentially a wrapper forgit-fast-import), except for the previous revision of the file, which is likely the patch base for the next revision.We however keep in memory one or two things for each file revision: a mapping of its mercurial SHA1 and the corresponding git SHA1 of the imported data, and, when there is one, the file metadata (containing information about file copy/renames) that lives as a header in the file data in mercurial, but can't be stored in the corresponding git blobs, otherwise we'd have irrelevant data in checkouts.
On the graph, this is where there is a steady and rather long increase of both live allocations and memory usage, in stairs for the latter.
In the
git cloneanalyzed here, there are 2.02M file revisions, 78k of which have copy/move metadata for a cumulated size of 8.5MB of metadata. The raw size of the file revisions in RawChunk format is 3.85GB. The expanded data size is 67GB. By the end of this phase, we made 622 million more allocator calls, and peaked at about 2.05GB of live data in about 6.9M allocations. Compared to the beginning of this phase, that added about 530MB in 5 million allocations.File metadata is stored in memory as python dicts, with 2 entries each, instead of raw form for convenience and future-proofing, so that would be at least 3 allocations each: one for each value, one for the dict, and maybe one for the dict storage ; their keys are all the same and are probably interned by python, so wouldn't count.
As mentioned above, we store a mapping of mercurial to git SHA1s, so for each file that makes 2 allocations, 4.04M total. Plus the 230k or 310k from metadata. Let's say 4.45M total. We're short 550k allocations, but considering the numbers involved, it would take less than one allocation per file on average to go over this count.
As for memory size, per this answer on stackoverflow, python strings have an overhead of 37 bytes, so each SHA1 (kept in hex form) will take 77 bytes (Note, that's partly why I didn't particularly care about storing them as binary form, that would only save 25%, not 50%). That's 311MB just for the SHA1s, to which the size of the mapping dict needs to be added. If it were a plain array of pointers to keys and values, it would take 2 * 8 bytes per file, or about 32MB. But that would be a hash table with no room for more items (By the way, I suspect the stairs that can be seen on the requested and in-use bytes is the hash table being
realloc()ed). Plus at least 290 bytes per dict for each of the 78k metadata, which is an additional 22M. All in all, 530MB doesn't seem too much of a stretch. - Importing manifests.
At this point, we're done receiving data from the server, so we begin by
dropping objects related to the bundle we got from the server. On the graph, I assume this is the big dip that can be observed after the initial increase in memory use, bringing us down to 5.6 million allocations and 1.92GB.Now begins the most time consuming process, as far as mozilla-central is concerned: transforming the manifests into git trees, while also storing enough data to be able to reconstruct manifests later (which is required to be able to pull from the mercurial server after the clone).
So for each manifest, we expand the RawChunk into the full manifest data, and generate new git trees from that. The latter is mostly performed by the
git-cinnabar-helperprocess. Once we're done pushing data about a manifest to that process, we drop the corresponding data, except when we know it will be required later as the delta base for a subsequent RevChunk (which can happen in bundle2).As with file revisions, for each manifest, we keep track of the mapping of SHA1s between mercurial and git. We also keep a DAG of the manifests history (contrary to git trees, mercurial manifests track their ancestry ; files do too, but git-cinnabar doesn't actually keep track of that separately ; it just relies on the manifests data to infer file ancestry).
On the graph, this is where the number of live allocations increases while both requested and in-use bytes decrease, noisily.
By the end of this phase, we made about 1 billion more allocator calls. Requested allocations went down to 1.02GB, for close to 7 million live allocations. Compared to the end of the dip at the beginning of this phase, that added 1.4 million allocations, and released 900MB. By now, we expect everything from the "Reading manifests" phase to have been released, which means we allocated around 620MB (1.52GB - 900MB), for a total of 3.26M additional allocations (1.4M + 1.86M).
We have a dict for the SHA1s mapping (345k * 77 * 2 for strings, plus the hash table with 345k items, so at least 60MB), and the DAG, which, now that I'm looking at memory usage, I figure has the one of the possibly worst structure, using 2 sets for each node (at least 232 bytes per set, that's at least 160MB, plus 2 hash tables with 345k items). I think 250MB for those data structures would be largely underestimated. It's not hard to imagine them taking 620MB, because really, that DAG implementation is awful. The number of allocations expected from them would be around 1.4M (4 * 345k), but I might be missing something. That's way less than the actual number, so it would be interesting to take a closer look, but not before doing something about the DAG itself.
Fun fact: the amount of data we're dealing with in this phase (the expanded size of all the manifests) is close to 2.9TB (yes, terabytes). With about 4700 seconds spent on this phase on a real clone (less with the release branch), we're still handling more than 615MB per second.
- Importing changesets.
This is where we finally create the git commits corresponding to the mercurial changesets. For each changeset, we expand its RawChunk, find the git tree we created in the previous phase that corresponds to the associated manifest, and create a git commit for that tree, with the right date, author, and commit message. For data that appears in the mercurial changeset that can't be stored or doesn't make sense to store in the git commit (e.g. the manifest SHA1, the list of changed files[*], or some extra metadata like the source of rebases), we keep some metadata we'll store in git notes later on.
[*] Fun fact: the list of changed files stored in mercurial changesets does not necessarily match the list of files in a `git diff` between the corresponding git commit and its parents, for essentially two reasons:
- Old buggy versions of mercurial have generated erroneous lists that are now there forever (they are part of what makes the changeset SHA1).
- Mercurial may create new revisions for files even when the file content is not modified, most notably during merges (but that also happened on non-merges due to, presumably, bugs).
... so we keep it verbatim.
On the graph, this is where both requested and in-use bytes are only slightly increasing.
By the end of this phase, we made about half a billion more allocator calls. Requested allocations went up to 1.06GB, for close to 7.7 million live allocations. Compared to the end of the previous phase, that added 700k allocations, and 400MB. By now, we expect everything from the "Reading changesets" phase to have been released (at least the raw data we kept there), which means we may have allocated at most around 700MB (400MB + 300MB), for a total of 1.5M additional allocations (700k + 840k).
All these are extra data we keep for the next and final phase. It's hard to evaluate the exact size we'd expect here in memory, but if we divide by the number of changesets (345k), that's less than 5 allocations per changeset and less than 2KB per changeset, which is low enough not to raise eyebrows, at least for now.
- Finalizing the clone.
The final phase is where we actually go ahead storing the mappings between mercurial and git SHA1s (all 2.7M of them), the git notes where we store the data necessary to recreate mercurial changesets from git commits, and a cache for mercurial tags.
On the graph, this is where the requested and in-use bytes, as well as the number of live allocations peak like crazy (up to 21M allocations for 2.27GB requested).
This is very much unwanted, but easily explained with the current state of the code. The way the mappings between mercurial and git SHA1s are stored is via a tree similar to how git notes are stored. So for each mercurial SHA1, we have a file that points to the corresponding git SHA1 through git links for commits or directly for blobs (look at the output of
git ls-tree -r refs/cinnabar/metadata^3if you're curious about the details). If I remember correctly, it's faster if the tree is created with an ordered list of paths, so the code created a list of paths, and then sorted it to send commands to create the tree. The former creates a newstrof length 42 and atupleof 3 elements for each and every one of the 2.7M mappings. With the 37 bytes overhead bystrinstance and the 56 + 3 * 8 bytes per tuple, we have at least 429MB wasted. Creating the tree itself keeps the corresponding fast-import commands in a buffer, where each command is going to be atupleof 2 elements: a pointer to a method, and astrof length between 90 and 93. That's at least another 440MB wasted.I already fixed the first half, but the second half still needs addressing.
Overall, except for the stupid spike during the final phase, the manifest DAG and the glibc allocator runaway memory use described in previous posts, there is nothing terribly bad with the git-cinnabar memory usage, all things considered. Mozilla-central is just big.
The spike is already half addressed, and work is under way for the glibc allocator runaway memory use. The manifest DAG, interestingly, is actually mostly useless. It's only used to track the heads of the DAG, and it's very much possible to track heads of a DAG without actually storing the entire DAG. In fact, that's what git-cinnabar already does for changeset heads... so we would only need to do the same for manifest heads.
One could argue that the 1.4GB of raw RevChunk data we're keeping in memory for later user could be kept on disk instead. I haven't done this so far because I didn't want to have to handle temporary files (and answer questions like "where to put them?", "what if there isn't enough disk space there?", "what if disk access is slow?", etc.). But the majority of this data is from manifests. I'm already planning changes in how git-cinnabar stores manifests data that will actually allow to import them directly, instead of keeping them in memory until files are imported. This would instantly remove 1.18GB of memory usage. The downside, however, is that this would be more CPU intensive: Importing changesets will require creating the corresponding git trees, and getting the stored manifest data. I think it's worth, though.
Finally, one thing that isn't obvious here, but that was found while analyzing why RSS would be going up despite memory usage going down, is that git-cinnabar is doing way too many reallocations and substring allocations.
So let's look at two metrics that hopefully will highlight the problem:
- The cumulated amount of requested memory. That is, the sum of all sizes ever given to
malloc,realloc,calloc, etc. - The compensated cumulated amount of requested memory (naming is hard). That is, the sum of all sizes ever given to
malloc,calloc, etc. exceptrealloc. Forrealloc, we only count the delta in size between what the size was before and after therealloc.
Assuming all the requested memory is filled at some point, the former gives us an upper bound to the amount of memory that is ever filled or copied (the amount that would be filled if no realloc was ever in-place), while the the latter gives us a lower bound (the amount that would be filled or copied if all reallocs were in-place).
Ideally, we'd want the upper and lower bounds to be close to each other (indicating few realloc calls), and the total amount at the end of the process to be as close as possible to the amount of data we're handling (which we've seen is around 3TB).
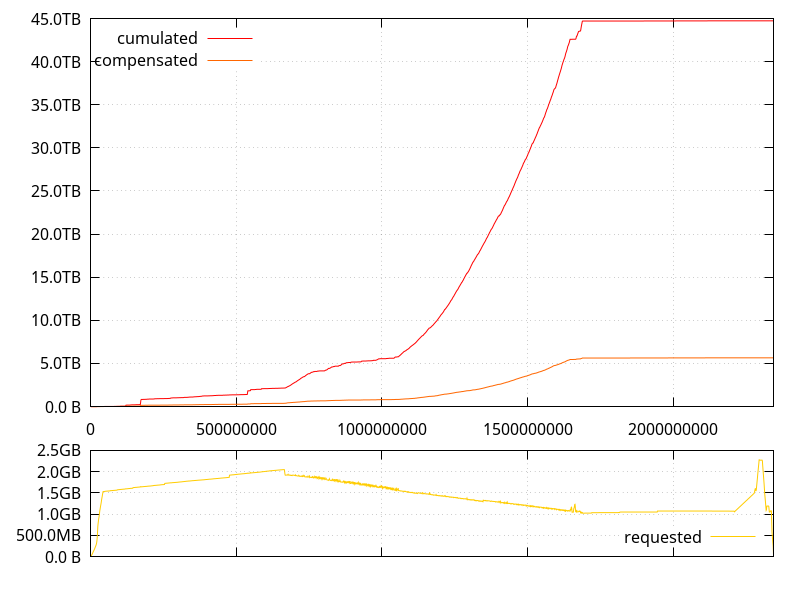
... and this is clearly bad. Like, really bad. But we already knew that from the previous post, although it's nice to put numbers on it. The lower bound is about twice the amount of data we're handling, and the upper bound is more than 10 times that amount. Clearly, we can do better.
We'll see how things evolve after the necessary code changes happen. Stay tuned.
2017-03-23 13:30:26+0900
Responses are currently closed, but you can trackback from your own site.
