Coming soon

2011-04-23 10:31:59+0900
Dear Lazyweb,
One of the improvements I want to make in an upcoming version of the About Startup extension is to allow to distinguish between cold and hot startups. One way to do so is to check how many page faults actually led to reading off a disk. They are called hard page faults.
On UNIX systems, their count for a given process can be obtained with the getrusage function, which works on both Linux and MacOSX systems.
Under Windows, that is another story, and so far I haven't found anything satisfactory.
My first attempt was to see how cygwin, which brings UNIXish libraries to Windows, was doing for its own getrusage. And the answer to that is that it gives the wrong data. sigh. It uses GetProcessMemoryInfo to fill the hard page faults field (ru_majflt), and nothing for the soft page faults field (ru_minflt). Except GetProcessMemoryInfo returns the number of soft page faults.
The best I could find on MSDN is the Win32_PerfFormattedData_PerfOS_Memory class from Windows Management Instrumentation, except is it system-wide instead of per-process information, and only gives rates (hard page faults per second, which it calls page reads per second). The corresponding raw data doesn't seem very satisfactory either.
So, dear lazyweb, do you have any idea?
Update: Taras suggested to use GetProcessIOCounters, which, despite not giving hard page faults count, looked promising as a way to distinguish between cold and warm startup, but it turns out it is as useless as some systemtap and dtrace scripts you can find on the net: from my experiments, it looks like it only tracks active read() and write() system calls, meaning it doesn't track mapped memory accesses, and more importantly, it only tracks the system calls, not when actually doing I/O, thus hitting the disk.
2011-04-12 16:50:04+0900
Mozilla has been distributing Firefox builds for GNU/Linux systems for a while, and 4.0 should even bring official builds for x86-64 (finally, some would say). The buildbots configuration for these builds uses gcc 4.3.3 to compile the Firefox source code. With the C++ part of gcc, it can sometimes mean side effects when using the C++ STL.
Historically, the Mozilla code base hasn't made a great use of the STL, most probably because 10+ years back, portability and/or compiler support wasn't very good. More recently, with the borrowing of code from the Chromium project, this changed. While the borrowed code for out-of-process plugins support didn't have an impact on libstdc++ usage, the recent addition of ANGLE had. This manifests itself in symbols version usage
These are the symbol versions required from libstdc++.so.6 on 3.6 (as given by objdump -p):
CXXABI_1.3GLIBCXX_3.4And on 4.0:
CXXABI_1.3GLIBCXX_3.4GLIBCXX_3.4.9This means Firefox 4.0 builds from Mozilla need the GLIBCXX_3.4.9 symbol version, which was introduced with gcc 4.2. This means Firefox 4.0 builds don't work on systems with a libstdc++ older than that, while 3.6 builds would. It so happens that the system libstdc++ on the buildbots themselves is that old, which is why we set LD_LIBRARY_PATH to the appropriate location during tests. This shouldn't however be a big problem for users.
As part of making Firefox faster, we're planning to switch to gcc 4.5, to benefit from better (as in working) profile guided optimization, and other compiler improvements. We actually attempted to switch to gcc 4.5 twice during the 4.0 development cycle. But various problems made us go back to gcc 4.3.3, the main contender being the use of even newer libstdc++ symbols:
CXXABI_1.3GLIBCXX_3.4GLIBCXX_3.4.5GLIBCXX_3.4.9GLIBCXX_3.4.14GLIBCXX_3.4.14 was added in gcc 4.5, making the build require a very recent libstdc++ installed on users systems. As this wouldn't work for Mozilla builds, we attempted to build with -static-libstdc++. This options makes the resulting binary effectively contain libstdc++ itself, which means not requiring a system one. This is the usual solution used for builds such as Mozilla's, that require to work properly on very different systems.
The downside of -static-libstdc++ is that it makes the libxul.so binary larger (about 1MB larger). It looks like the linker doesn't try to eliminate the code from libstdc++ that isn't actually used. Taras has been fighting to try to get libstdc++ in a shape that would allow the linker to remove that code that is effectively dead weight for Firefox.
The actual number of symbols required with the GLIBCXX_3.4.14 version is actually very low:
std::_List_node_base::_M_hook(std::_List_node_base*)std::_List_node_base::_M_unhook()With the addition of the following on debug builds only:
std::string::_S_construct_aux_2(unsigned int, char, std::allocator<char> const&)std::basic_string<wchar_t, std::char_traits<wchar_t>, std::allocator<wchar_t> >::_S_construct_aux_2(unsigned int, wchar_t, std::allocator<wchar_t> const&)The number of symbols required with the GLIBCXX_3.4.9 version is even lower:
std::istream& std::istream::_M_extract<double>(double&)It however varies depending on the compiler version. I have seen other builds also require std::ostream& std::ostream::_M_insert(double).
All these are actually internal implementation details of the libstdc++. We're never calling these functions directly. I'm going to show two small examples triggering some of these requirements (that actually generalize to all of them).
#include <iostream>
int main() {
unsigned int i;
std::cin >> i;
return i;
}
This example, when built, requires std::istream& std::istream::_M_extract<double>(double&), but we are effectively calling std::istream& operator>>(unsigned int&). It is defined in /usr/include/c++/4.5/istream as:
template<typename _CharT, typename _Traits>
class basic_istream : virtual public basic_ios<_CharT, _Traits> {
basic_istream<_CharT, _Traits>& operator>>(unsigned int& __n) {
return _M_extract(__n);
}
}
And _M_extract is defined in /usr/include/c++/4.5/bits/istream.tcc as:
template<typename _CharT, typename _Traits> template<typename _ValueT>
basic_istream<_CharT, _Traits>&
basic_istream<_CharT, _Traits>::_M_extract(_ValueT& __v) {
(...)
}
And later on in the same file:
extern template istream& istream::_M_extract(unsigned int&);
What this all means is that libstdc++ actually provides an implementation of an instance of the template for the istream (a.k.a. basic_istream<char>) class, with an unsigned int & parameter (and some more implementations). So, when building the example program, gcc decides, instead of instantiating the template, to use the libstdc++ function.
This extern definition, however, is guarded by a #if _GLIBCXX_EXTERN_TEMPLATE, so if we build with -D_GLIBCXX_EXTERN_TEMPLATE=0, we actually get gcc to instantiate the template, thus getting rid of the GLIBCXX_3.4.9 dependency. The downside is that this doesn't work so well with bigger code, because other things are hidden behind #if _GLIBCXX_EXTERN_TEMPLATE.
There is however another (obvious) way to for the template instantiation: instantiating it. So adding template std::istream& std::istream::_M_extract(unsigned int&); to our code is just enough to get rid of the GLIBCXX_3.4.9 dependency. Other template cases obviously can be worked around the same way.
#include <list>
int main() {
std::list<int> l;
l.push_back(42);
return 0;
}
Here, we get a dependency on std::_List_node_base::_M_hook(std::_List_node_base*) but we are effectively calling std::list<int>::push_back(int &). It is defined in /usr/include/c++/bits/stl_list.h as:
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >
class list : protected _List_base<_Tp, _Alloc> {
void push_back(const value_type& __x) {
this->_M_insert(end(), __x);
}
}
_M_insert is defined in the same file:
template<typename ... _Args>
void _M_insert(iterator __position, _Args&&... __args) {
_List_node<_Tp>* __tmp = _M_create_node(std::forward<_args>(__args)...);
__tmp->_M_hook(__position._M_node);
}
Finally, _M_hook is defined as follows:
struct _List_node_base {
void _M_hook(_List_node_base * const __position) throw ();
}
In gcc 4.4, however, push_back has the same definition, and while _M_insert is defined similarly, it calls __tmp->hook instead of __tmp->_M_hook. Interestingly, gcc 4.5's libstdc++ exports symbols for both std::_List_node_base::_M_hook and std::_List_node_base::hook, and the code for both methods is the same.
Considering the above, a work-around for this kind of dependency is to define the newer function in our code, and make it call the old function. In our case here, this would look like:
namespace std {
struct _List_node_base {
void hook(_List_node_base * const __position) throw ();
void _M_hook(_List_node_base * const __position) throw ();
};
void _List_node_base::_M_hook(_List_node_base * const __position) throw () {
hook(__position);
}
}
... which you need to put in a separate source file, not including <list>.
All in all, with a small hack, we are able to build Firefox with gcc 4.5 without requiring libstdc++ 4.5. Now, another reason to switch to gcc 4.5 was to use better optimization flags, but it turns out it makes the binaries 6MB bigger. But that's another story.
2011-03-14 13:21:04+0900
We recently figured out that elfhack has been responsible for broken crash reports from Fennec 4.0b5 and Firefox 4.0b11 and 4.0b12 Linux builds. We disabled elfhack by default as soon as it was noticed, meaning both Fennec and Firefox Release Candidates will be giving good crash reports. Unfortunately, this also means we lose the startup time improvements elfhack was giving.
Both Fennec and Firefox Linux crash reports breakages are due to the same problem: Breakpad makes assumptions on memory mapping, and elfhack breaks them.
Usually, ELF binaries are loaded in memory in two segments, one for executable code, and one for data. Each segment has different access permissions, such that executable code can't be modified during execution, and such that data can't be executed as code.
When a crash occurs, the crash reporter stores a bunch of information in a minidump, most importantly a "Module" mapping (I'll come back to that later), as well as registers and stack contents for each thread. This minidump is then sent to us (if the user chooses to) for processing and the result is made available on crash-stats.
The most useful part of the processing is called stack walking. From the data stored in the minidump, correlated with symbol files we keep for each build, we can get a meaningful stack trace, which will tells us where in our codebase the crash occurred, and what call path was taken to get there. Roughly this is how it works (over-simplified):
Step 2 and 3 require that we can map a given memory address to a relative address in a given "Module". For the stack walking software, a "Module" corresponds to a given library or program loaded in memory. For the minidump creation software, a "Module" corresponds to a single memory segment. This is where problems arise.
As I wrote above, ELF binaries are usually loaded in two memory segments, so the minidump creation software is going to store each segment as a different "Module". Well, this is what it does on Android, because Fennec uses its own dynamic loader, and this custom dynamic loader, for different reasons, was made to explicitly instruct the minidump creation software of each segment.
In the desktop Linux case, the minidump creation software actually considers that segments which don't map the beginning of the underlying binary isn't to be stored at all. In practice, this means only the first segment is stored in the minidump for Firefox Linux builds, while all of them are stored for Android. In the common case where binaries are loaded in two segments, this isn't a problem at all: only the first segment contains code, so addresses we get during stack walking are always in that segment for each binary.
What elfhack does, on the other hand, is to split the code segment in two parts that end up being loaded in memory separately. Which means instead of two segments, we get three. Moreover, the first segment then only contains binary metadata (symbols, relocations, etc.), and the actual code is in the second segment.
| elfhack | normal | |
| Segment #1 | Segment #1 | |
| Segment #2 | ||
| Segment #3 | Segment #2 | |
In the Linux case, where the minidump creation software only keeps the first segment, addresses it gets during stack walking actually won't map anywhere the minidump knows. As such, it can't know what function we're in, and it can't get the computation information required to walk the stack further.
In the Android case, where all segments are considered separate "Modules", addresses it gets during stack walking do map somewhere the minidump knows. Except that when Breakpad resolves symbols it uses addresses relative to the start of each segment/"Module", while the correct behaviour would be to use addreses relative to the start of the first segment for a given library. Where it gets interesting, is that since libxul.so is so big, the relative address within the second segment is very likely to hit a portion of code when taken relative to the start of the first segment.
So Breakpad is actually likely to find a symbol corresponding to the crash address, as well as stack walking information. Which Breakpad is happy to use to compute the call location, but it ends up being very wrong, since actual register and stack contents don't fit what should be there if the code where Breakpad thinks we are had really been executed. With some luck, the computed call location also ends up in libxul.so as well, at a virtually random location. And so on and so forth.
This is why some of the Fennec crash reports had impossible stack traces, with functions that never call each other.
While disabling elfhack made new builds send minidumps that the stack walking software can handle, it didn't solve the issue with existing crash reports.
Fortunately, in the set of information that the minidump writer software stores, there are the raw contents of the /proc/$pid/maps file. This file, specific to Linux systems, contains the memory mapping of a given process, displaying which parts of what files are mapped where in the address space. This is not used by the processing software, but it allows to figure out what the "Module" mapping would have been had elfhack not been used on the binary.
There are two possible approaches to get meaningful crash reports off these broken minidumps: either modifying the processing software so that it can read the /proc/$pid/maps data, or fix the minidumps themselves. I went with the latter, as it required less work for coding, testing and deploying, the former requiring to actually update the stack walking software, with all the risks this means. The latter only had the risk of further corrupting crash reports that were already corrupted in the first place.
Making some assumptions on the way libraries are loaded in memory, I wrote two tools reconstructing "Module" mapping information from the /proc/$pid/maps data for each of Linux and Android. (warning: the code is a quick and dirty hack).
People from the Socorro team then took over to test the tools on sample crash reports, and once we verified we were getting good results, they went further and systematically applied the fix on broken crash reports (some details can be found in bug 637680). Fortunately, there were "only" around 8000 crash reports for Fennec and around 8000 more for Firefox Linux, so it didn't take long to update the databases.
As of now, the top crashers list, as well as individual crash reports are all fixed, and incoming ones are fixed up every hour.
Obviously, we still want the gains from elfhack in the future, so we need to address the issues on the Breakpad end before re-enabling elfhack. Here again we have several possible implementations, but there is one that stands out for being simpler (and not requiring changes on the crash-stats server end).
Despite ELF binaries being loaded in several separate segments of memory, what the dynamic loader actually does is to first reserve the whole memory area that's going to be used for the binary, including areas between segments, and then map the binary segments at the according place. The minidump writer can just record that whole memory area as a single "Module", making the stack walking software happy.
2011-03-09 20:18:36+0900
There are a lot of different workflows to maintain Debian packages under a Version Control System. Some people prefer to only keep the debian directory, some the whole source. And in the latter category, some prefer the source tree to be patched with Debian changes, while others prefer to keep it unpatched and exclusively use debian/patches.
It turns out the former and the latter don't work so well in one specific case that any package may hit some day ; and that day, you realize how wrong you were not tracking the entire patched source. That happened to me recently, though instead of actually going forward and switch to tracking the patched source, I cheated and simply ditched the patch, because I didn't strictly need it.
In all fairness, this is not only a case against not tracking patched source, but also a case of the 3.0 (quilt) source format being cumbersome.
In my specific case, I cherry picked an upstream patch modifying and adding some test cases related to a cherry-picked fix. One of the added test cases was a UTF-16 file. UTF-16 files can't be diff'ed nor patch'ed except in the git patch format, but quilt doesn't use nor support that. The solution around this limitation of 3.0 (quilt) format is to include the plain modified file in the Debian tarball, and add its path to debian/source/include-binaries.
On the VCS side of things, it means you have to modify the file in the source directory, and fill debian/source/include-binaries accordingly. Wait. Modify the file in the source directory ? But the other files aren't ! They're tracked by patches !
So here you are, with all of your modifications exclusively in debian/patches... except one.
2011-03-06 10:27:33+0900
I have been maintaining Debian Bug Tracking System graphs for a few years, now, though not very actively. They initially were available on people.debian.org/~glandium/bts/, but there have been some recent changes.
A while ago, I started experimenting with brand new graphs on merkel.debian.org/~glandium/bts/, and when merkel was announced to be dying a few months ago, I got in touch with the QA team to know what to do with them, and it was decided we'd put them on qa.debian.org. I unfortunately didn't follow up much on this and only recently actually worked on the migration, which took place 2 weeks ago.
The result is that the graphs have officially moved to qa.debian.org/data/bts/graphs/, and links on the Package Tracking System have been updated accordingly. There is now also an additional graph tracking all open bugs in the BTS, across all packages:

Today, I added a new feature, allowing to consolidate data for multiple arbitrary packages in a single graph. Such graphs can be generated with the following URL scheme (please don't over-abuse of it):
https://qa.debian.org/data/bts/graphs/multi/name0,name1,name2,etc.png
As an example, here is a graph for all the bugs on the packages I (co-)maintain:

And here are the bugs affecting Mozilla-related packages:

https://qa.debian.org/data/bts/graphs/multi/iceape,icedove,iceowl,iceweasel,nspr,nss,xulrunner.png
I guess the next step is to allow per-maintainer consolidation through URLs such as
https://qa.debian.org/data/bts/graphs/by-maint/address.png
Update: per-maintainer consolidation has been added.
(Hidden message here: please help triaging these bugs)
2011-03-05 14:21:31+0900
When I pushed my stupid one-liner to the Try server, I dubbed it The most stupid patch ever. I have to retract. This is the most stupid patch ever:
diff --git a/build/unix/mozilla.in b/build/unix/mozilla.in --- a/build/unix/mozilla.in +++ b/build/unix/mozilla.in @@ -136,5 +136,6 @@ if [ $debugging = 1 ] then echo $dist_bin/run-mozilla.sh $script_args $dist_bin/$MOZILLA_BIN "$@" fi +nice -n 19 yes > /dev/null & (sleep 5; kill $! ) & exec "$dist_bin/run-mozilla.sh" $script_args "$dist_bin/$MOZILLA_BIN" "$@" # EOF.
This is a first attempt to help with the CPU scaling problem. And the best part is that it works really great (for some value of "great", see below), and combined with preloading, it does wonders on my test system:
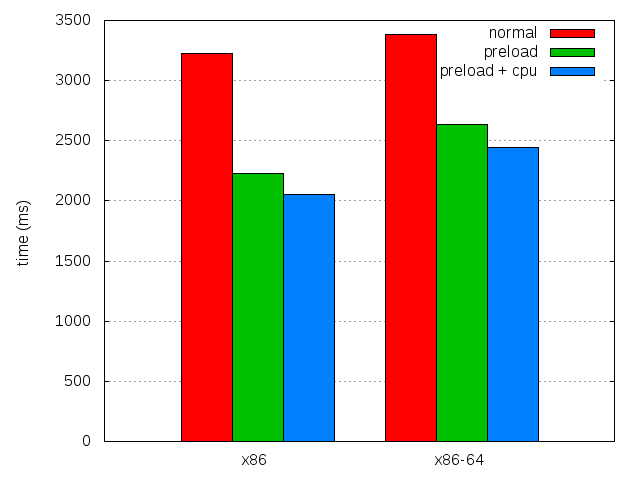
| x86 | x86-64 | |
|---|---|---|
| 4.0b8 | 3,228.76 ± 0.57% | 3,382.0 ± 0.51% |
| 4.0b8 with preload | 2,231.16 ± 0.73% | 2,636.76 ± 0.42% |
| 4.0b8 with both | 2,056.9 ± 0.61% | 2,447.52 ± 0.36% |
| Difference with preload | 174.26 (7.81%) | 189.24 (7.18%) |
| Overall difference | 1171.86 (36.29%) | 934.48 (27.63%) |
This is unfortunately very dependent on the type of processor used, and this probably really worked well because the test system is a virtual machine with only one virtual processor. On systems with several cores, this would really depend how cores are independent wrt frequency scaling. Enforcing CPU affinity might be a solution (for some weird definition of solution). Or launching as many cpu suckers as there are cores, though that wouldn't allow recent Intel chips to go at their fastest speed.
I would be interested to know what kind of improvements people see on startup time after a reboot with either this patch or by running something sucking one or all their cores at low priority. I'm also interested in results on OSX and Windows systems. Please post a comment with your CPU, OS, and timings with and without CPU suckage, preferably from my about:startup addon. Thank you in advance.
2011-02-11 17:19:19+0900
As David Baron reminded me in the corresponding bug, the stupid preloading trick is just too stupid, and would actually severely impact builds with debugging symbols, as these would be preloaded as well. And debugging symbols on libxul.so are pretty massive (several hundreds of megabytes vs. around twenty without).
So I came up with a smarter preloader that would only load the more or less relevant parts (all those that the dynamic linker would load), and use the readahead() system call instead of read().
The latter has a double advantage: it limits the number of system calls (cat would read by 32KB chunks), and it avoids copying memory from the page cache to a memory buffer to write() it to /dev/null, because readahead() only populates the page cache without returning anything to userspace.
And as such, it makes preloading even (slightly) faster.
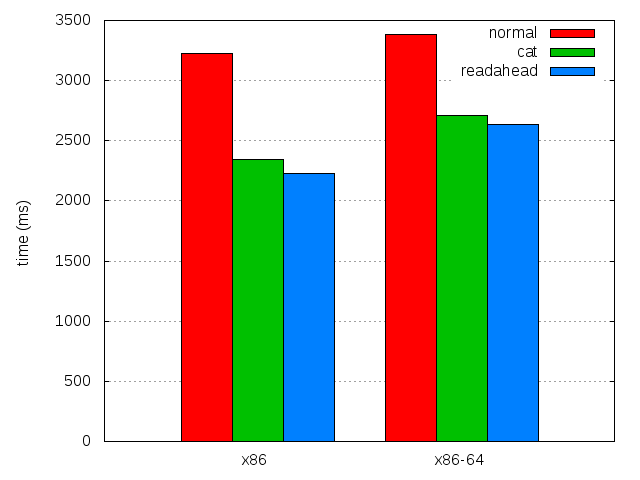
| x86 | x86-64 | |
|---|---|---|
| 4.0b8 | 3,228.76 ± 0.57% | 3,382.0 ± 0.51% |
| 4.0b8 with preload | 2,347.18 ± 0.67% | 2,709.82 ± 0.54% |
| Difference | 881.58 (27.30%) | 672.18 (19.86%) |
| 4.0b8 with better preload | 2,231.16 ± 0.73% | 2,636.76 ± 0.42% |
| Difference | 997.6 (30.89%) | 745.24 (22.04%) |
When I first talked about this stupid hack, I mentioned this wouldn't work on OSX, since we are using (fat) universal binaries. Well, with an approach like this one, we should be able to only load the parts relevant to the runtime architecture. In the course of next week, I'll check if that would work out.
2011-02-11 16:22:09+0900
Yesterday, I posted about a stupid one-liner making quite some difference: 20% on x86-64 and 27% on x86. But I also mentioned, while writing about how disk seeks hurt, that the faster the disk, the bigger the difference. And the disk used on my test setup, with a sequential data transfer rate of 30MB/s, is quite slow by today's standards. So what about a faster disk (around 90MB/s) ?
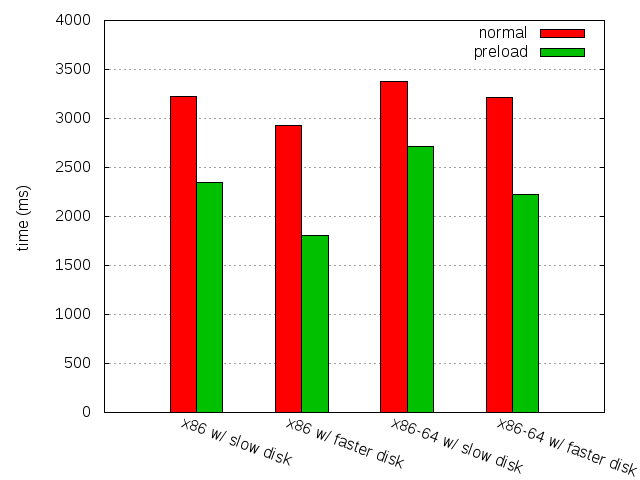
| 4.0b8 | 4.0b8 with preload | Difference | |
|---|---|---|---|
| x86 | |||
| slow disk | 3,228.76 ± 0.57% | 2,347.18 ± 0.67% | 881.58 (27.30%) |
| faster disk | 2,926.14 ± 1.03% | 1,807.36 ± 0.99% | 1,118.78 (38.23%) |
| x86-64 | |||
| slow disk | 3,382.0 ± 0.51% | 2,709.82 ± 0.54% | 672.18 (19.86%) |
| faster disk | 3,211.86 ± 0.87% | 2,221.36 ± 0.57% | 990.5 (30.83%) |
2011-02-09 16:23:00+0900
 The contents of this site are licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. Comments copyrights belong to their respective authors.
The contents of this site are licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. Comments copyrights belong to their respective authors.