Mozilla Build System: past, present and future
The Mozilla Build System has, for most of its history, not changed much. But, for a couple years now, we've been, slowly and incrementally, modifying it in quite extensive ways. This post summarizes the progress so far, and my personal view on where we're headed.
Recursive make
The Mozilla Build System has, all along, been implemented as a set of recursively traversed Makefiles. The way it has been working for a very long time looks like the following:
- For each tier (group of source directories) defined at the top-level:
- For each subdirectory in current tier:
- Build the
exporttarget recursively for each subdirectory defined in Makefile. - Build the
libstarget recursively for each subdirectory defined in Makefile.
- Build the
- For each subdirectory in current tier:
The typical limitation due to the above is that some compiled tests from a given directory would require a library that's not linked until after the given directory is recursed, so another target was later added on top of that (tools).
There was not much room for parallelism, except in individual directories, where multiple sources could be built in parallel, but never would sources from multiple directories be built at the same time. So, for a bunch of directories where it was possible, special rules were added to allow that to happen, which led to interesting recursions:
- For each of
export,libs, andtools:- Build the target in the subdirectories that can be built in parallel.
- Build the target in the current directory.
- Build the target in the remaining subdirectories.
This ensured some extra fun with dependencies between (sub)directories.
Apart from the way things were recursed, all sorts of custom build rules had piled up, some of which relied on things in other directories having happened beforehand, and the build system implementation itself relied on some quite awful things (remember allmakefiles.sh?)
Gradual Overhaul
Around two years ago, we started a gradual overhaul of the build system.
One of the goals was to move away from Makefiles. For various reasons, we decided to go with our own kind-of-declarative (but really, sandboxed python) format (moz.build) instead of using e.g. gyp. The more progress we make on the build system, and the more I think this was the right choice.
Anyways, while we've come a long way and converted a lot of Makefiles to moz.build, we're not quite there yet:
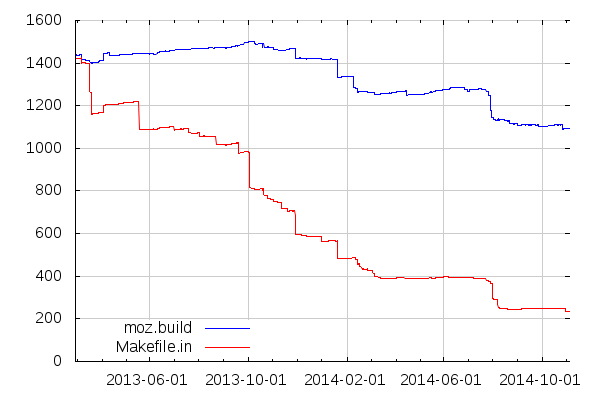
One interesting thing to note in the above graph is that we've also been reducing the overall number of moz.build files we use, by consolidating some declarations. For example, some moz.build files now declare source or test files from their subdirectories directly, instead of having one file per directory declare sources and test files local to their own directory.
Pseudo derecursifying recursive Make
Neologism aside, one of the ideas to help with the process of converting the build system to something that can be parallelized more massively was to reduce the depth of recursion we do with Make. So that instead of a sequence like this:
- Entering directory A
- Entering directory A/B
- Leaving directory A/B
- Entering directory A/C
- Entering directory A/C/D
- Leaving directory A/C/D
- Entering directory A/C/E
- Leaving directory A/C/E
- Entering directory A/C/F
- Leaving directory A/C/F
- Leaving directory A/C
- Entering directory A/G
- Leaving directory A/G
- Leaving directory A
- Entering directory H
- Leaving directory H
We would have a sequence like this:
- Entering directory A
- Leaving directory A
- Entering directory A/B
- Leaving directory A/B
- Entering directory A/C
- Leaving directory A/C
- Entering directory A/C/D
- Leaving directory A/C/D
- Entering directory A/C/E
- Leaving directory A/C/E
- Entering directory A/C/F
- Leaving directory A/C/F
- Entering directory A/G
- Leaving directory A/G
- Entering directory H
- Leaving directory H
For each directory there would be a directory-specific target per top-level target, such as A/B/export, A/B/libs, etc. Essentially those targets are defined as:
%/$(target): $(MAKE) -C $* $(target)
And each top-level target is expressed as a set of dependencies, such as, in the case above:
A/B/libs: A/libs A/C/libs: A/B/libs A/C/D/libs: A/C/libs A/C/E/libs: A/C/D/libs A/C/F/libs: A/C/E/libs A/G/libs: A/C/F/libs H/libs: A/G/libs libs: H/libs
That dependency list, instead of being declared manually, is generated from the "traditional" recursion declaration we had in moz.build, through the various *_DIRS variables. I'll skip the gory details about how this replicated the weird subdirectory orders I mentioned above when you had both PARALLEL_DIRS and DIRS. They are irrelevant today anyways.
You'll also note that this also removed the notion of tier, and the entirety of the tree is dealt with for each target, instead of iterating all targets for each group of directories.
[But note that, confusingly, but for practical reasons related to the amount of code changes required, and to how things were incrementally set in place, those targets are now called tiers]
From there, parallelizing parts of the build only involves reorganizing those Make dependencies such that Make can go in several subdirectories at once, the ultimate goal being:
libs: A/libs A/B/libs A/C/libs A/C/D/libs A/C/E/libs A/C/F/libs A/G/libs A/H/libs
But then, things in various directories may need other things built in different directories first, such that additional dependencies can be needed, for example:
A/B/libs A/C/libs: A/libs A/H/libs: A/G/libs
The trick is that those dependencies can in many cases be deduced from the contents of moz.build. That's where we are today, for example, for everything related to compilation: We added a compile target that deals with everything C/C++ compilation, and we have dependencies between directories building objects and directories building libraries and executables that depend on those objects. You can have a taste yourself:
$ mach clobber $ mach configure $ mach build export $ mach build -C / toolkit/library/target
[Note, the compile target is actually composed of two sub-targets, target and host.]
The third command runs the export target on the whole tree, because that's a prerequisite that is not expressed as a make dependency yet (it would be too broad of a dependency anyways).
The last command runs the toolkit/library/target target at the top level (as opposed to mach build toolkit/library/target, which runs the target target in the toolkit/library directory). That will build libxul, and everything needed to link it, but nothing else unrelated.
All the other top-level targets have also received this treatment to some extent:
- The
exporttarget was made entirely parallel, although it keeps some cross-directory dependencies derived from the historical traversal data. - The
libstarget is still entirely sequential, because of all the horrible rules in it that may or may not depend on the historical traversal order. - A parallelized
misctarget was recently created to receive all the things that are currently done as part of thelibstarget that are actually safe to be parallelized (another reason for creating this new target is thatlibsis now a misnomer, since everything related to libraries is now part ofcompile). Please feel free to participate in the effort to movelibsrules there. - The
toolstarget is still sequential, but see below.
Although, some interdependencies that can't be derived yet are currently hardcoded in config/recurse.mk.
And since the mere fact of entering a directory, figuring out if there's anything to do at all, and leaving a directory takes some time on builds when only a couple things changed, we also skip some directories entirely by making them not have a directory/target target at all:
exportandlibsonly traverse directories where there is aMakefile.infile, or where themoz.buildfile sets variables that do require something to be done in those targets.compileonly traverses directories where there is something to compile or link.misconly traverses directories with an explicitHAS_MISC_RULE = Truewhen they have aMakefile.in, or with amoz.buildsetting variables affecting themisctarget.toolsonly traverses directories that contain a Makefile.in containingtools::(there's actually a regexp, but in essence, that's it).
Those skipping rules allow to only traverse, taking numbers from a local Linux build, as of a couple weeks ago:
- 186 directories during
libs, - 472 directories during
compile, - 161 directories during
misc, - 382 directories during
libs, - 2 directories during
tools.
instead of 850 for each.
In the near future, we may want to change export and libs to opt-ins, like misc, instead of opt-outs.
Alternative build backends
With more and more declarations in moz.build, files, we've been able to build up some alternative build backends for Eclipse and Microsoft Visual Studio. While they still are considered experimental, they seem to work well enough for people to take advantage of them in some useful ways. They however still rely on the "traditional" Make backend to build various things (to the best of my knowledge).
Ultimately, we would like to support entirely different build systems such as ninja or tup, but at the moment, many things still heavily rely on the "traditional" Make backend. We're getting close to having everything related to compilation available from the moz.build declarations (ignoring third-party code, but see further below), but there is still a long way to go for other things.
In the near future, we may want to implement hybrid build backends where compilation would be driven by ninja or tup, and the rest of the build would be handled by Make. However, my feeling is that the Make backend is fast enough for compilation and ninja doesn't bring enough other than performance that it's not worth investing in a ninja backend. Tup is different because it does solve some of the problems with incremental builds.
While on the topic of being close to having everything related to compilation available from moz.build declarations, closing in on this topic would allow, more than such hybrid build systems, to better integrate tools such as code static analyzers.
Unified C/C++ sources
Compiling C code, and even more compiling C++ code, involves reading the same headers an important number of times. In C++, that usually also means instantiating the same templates and compiling the same inline methods numerous times.
So we've worked around this by creating "unified sources" that just #include the actual source files, grouping them 16 by 16 (except when specified otherwise).
This reduced build times drastically, and, interestingly, reduced the size of DWARF debugging symbols as well. This does have a couple downsides, though. It allows #include impurity in the code in such a way that e.g. changes in the file groups can lead to subtle build failures. It also makes incremental builds significantly slower in parts of the tree where compiling one file is already somehow slow, so doing 16 at a time can be a drag for people working on that code. This is why we're considering decreasing the number for the javascript engine in the near future. We should probably investigate where else building one unified source is slow enough to be a concern. I don't think we can rely on people actively complaining about it, they've been too used to slow build times to care to file bugs about it.
Relatedly, our story with #include is suboptimal to say the least, and several have been untangled, but there's still a long tail. It's a hard problem to solve, even with tools like IWYU.
Fake libraries
For a very long time, the build system was building intermediate static libraries, and then was linking them together to form shared libraries. This is how the main components were built in the old days before libxul (remember libgklayout?), and was how libxul built when it was created. For various reasons, ranging from disk space waste to linker inefficiencies, this was replaced by building fake libraries, that only reference the objects that would normally be contained in the static library that used to be built. This later was changed to use a more complex system allowing more flexibility.
Fast-forward to today, and with all the knowledge from moz.build, one of the usecases of that more complex system was made moot, and in the future, those fake libraries could be generated as build backend files instead of being created during the build.
Specialized incremental builds
When iterating C/C++ code patches, one usually needs to (re)compile often. With the build system having the overhead it has, and rebuilding with no change taking many seconds (it has been around a minute for a long time on my machine and is now around half of that, although, sadly, I had got it down to 20 seconds but that regressed recently, damn libs rules), we also added a special rule that only handles header changes and rebuilding objects, libraries and executables.
That special rule is invoked as:
$ mach build binaries
And takes about 3.5s on my machine when there are no changes. It used to be faster thanks to clever tricks, but that was regressed on purpose. That's a trade-off, but linking libxul, which most code changes require, takes much longer than that anyways. If deemed necessary, the same clever tricks could be restored.
While we work to improve the overall build experience, in the near future we should have one or more special rules for non-compilation use-cases. For Firefox frontend developers, the following command may do part of the job:
$ mach build -C / chrome
but we should have some better and more complete commands for them and e.g. Firefox Android developers.
We also currently have a build option allowing to entirely skip everything that is compilation related (--disable-compile-environment), but it is currently broken and is only really useful in few use cases. In the near future, we need build modes that allow to use e.g. nightly builds as if they were the result of compiling C++ source. This would allow some classes of developers to skip compilations altogether, which are an unnecessary overhead for them at the moment, since they need to compile at least once (and with all the auto-clobbers we have, it's much more than that).
Localization
Related to the above, the experience of building locale packs and repacks for Firefox is dreadful. Even worse than that, it also relies on a big pile of awful Make rules. It probably is, along with the code related to the creation of Firefox tarballs and installers, the most horrifying part of the build system. Its entanglement with release automation also makes improving the situation unnecessarily difficult.
While there are some sorts of tests running on every push, there are many occasions where those tests fail to catch regressions that lead to broken localized builds for nightlies, or worse on beta or release (which, you'll have to admit, is a sadly late a moment to find such regressions).
Something really needs to be done about localization, and hopefully the discussions we'll have this week in Portland will lead to improvements in the short to medium term.
Install manifests
The build system copies many files during the build. From the source directory to the "object" directory. Sometimes in $(DIST)/somedir, sometimes elsewhere. Sometimes in both or more. On non-Windows systems, copies are replaced by symbolic links. Sometimes not. There are also files that are preprocessed during the build.
All those used to be handled by Make rules invoking $(NSINSTALL) on every build. Even when the files hadn't changed. Most of these were replaced by some Makefile magic, but many are now covered with so-called "install manifests".
Others, defined in jar.mn files, used to be added to jar files during the build. While those jars are not created anymore because of omni.ja, the corresponding content is still copied/symlinked and defined in jar.mn.
In the near future, all those should be switched to install manifests somehow, and that is greatly tied to solving part of the localization problem: currently, localization relies on Make overrides that moz.build can't know about, preventing install manifests being created and used for the corresponding content.
Faster configure
One of the very first things the build system does when a build starts from scratch is to run configure. That's a part of the build system that is based on the antiquated autoconf 2.13, with 15+ years of accumulated linear m4 and shell gunk. That's what detects what kind of compiler you use, how broken it is, how broken its headers are, what options you requested, what application you want to build, etc.
Topping that, it also invokes configure from third-party software that happen to live in the tree, like ICU or jemalloc 3. Those are also based on autoconf, but in more recent versions than 2.13. They are also third-party, so we're essentially only importing them, as opposed to actively making them bigger for those that are ours.
While it doesn't necessarily look that bad when running on e.g. Linux, the time it takes to run all this pile of shell scripts is painfully horrible on Windows (like, taking more than 5 minutes on automation). While there's still a lot to do, various improvements were recently made:
- Some classes of changes (such as modifying
configure.in) make the build system re-runconfigure. It used to trigger everyconfigureto run again, but now only re-runs a relevant subset. - They used to all run sequentially, but apart from the top-level one, which still needs to run before all the others, they now all run in parallel. This cut
configuretimes almost in half on Windows clobber builds on automation.
In the future, we want to get rid of autoconf 2.13 and use smart lazy python code to only run the tests that are relevant to the configure options. How this would all exactly work has, as of writing, not been determined. It's been on my list of things to investigate for a while, but hasn't reached the top. In the near future, though, I would like to move all our autoconf code related to the build toolchain (compiler and linker) to some form of python code.
Zaphod beeblebuild
There are essentially two main projects in the mozilla-central repository: Firefox/Gecko and the Javascript engine. They use the same build system in many ways. But for a very long time, they actually relied on different copies of the same build system files, like config/rules.mk or build/autoconf/*.m4. And we had a check-sync-dirs script verifying that both projects were indeed using the same file contents. Countless times, we've had landings forgetting to synchronize the files and leading to a check-sync-dirs error during the build. I plead guilty to have landed such things multiple times, and so did many other people.
Those days are now long gone, but we currently rely on dirty tricks that still keep the Firefox/Gecko and Javascript engine build systems half separate. So we kind of replaced a conjoined-twins system with a biheaded system. In the future, and this is tied to the section above, both build systems would be completely merged.
Build system interface
Another goal of the build system changes was to make the build and test experience better. Especially, running tests was not exactly the most pleasant experience.
A single entry point to the build system was created in the form of the mach tool. It simplifies and self-documents many of the workflows that required arcane knowledge.
In the future, we will deprecate the historical build system entry points, or replace their implementation to call mach. This includes client.mk and testing/testsuite-targets.mk.
moz.build
Yet another goal of the build system changes was to improve the experience developers have when adding code to the tree. Again, while there is still a lot to be done on the subject, there have been a lot of changes in the past year that I hope have made developer's lives easier.
As an example, adding new code to libxul previous required:
- Creating a
Makefile.infile- Defining a
LIBRARY_NAME. - Defining which sources to build with
CPPSRCS,CSRCS,CMMSRCS,SSRCSorASFILES, using the right variable name for the each source type (C++ or C or Obj-C, or assembly. By the way, did you know there was a difference betweenSSRCSandASFILES?).
- Defining a
- Adding something like
SHARED_LIBRARY_LIBS += $(call EXPAND_LIBNAME_PATH,libname,$(DEPTH)/path)totoolkit/library/Makefile.in.
Now, adding new code to libxul requires:
- Creating a
moz.buildfile- Defining which sources to build with
SOURCES, whether they are C, C++ or other. - Defining
FINAL_LIBRARYto'xul'.
- Defining which sources to build with
This is only a simple example, though. There are more things that should have gotten easier, especially since support for templates landed. Templates allowed to hide some details such as dependencies on the right combination of libxul, libnss, libmozalloc and others when building programs or XPCOM components. Combined with syntactic sugar and recent changes to how moz.build data is handled by build backends, we could, in the future, allow to define multiple targets in a single directory. Currently, if you want to build e.g. a library and a program or multiple libraries in the same directory, well, essentially, you can't.
Relatedly, moz.build currently suffers from how it was grown from simply moving definitions from Makefile.in., and how those definitions in Makefile.in were partly tied to how Make works, and how config.mk and rules.mk work. Consolidating CPPSRCS, CSRCS and other variables into a single SOURCES variable is something that should be done more broadly, and we should bring more consistency to how things are defined (for example NO_PGO vs. no_pgo depending on the context, etc.). Incidentally, I think those changes can be made in a way that simplifies the build backend python code.
Multipass
Some build types, while unusual for developers to do locally on their machine, happen regularly on automation, and are done in awful or inefficient ways.
First, Profile Guided Optimized (PGO) builds. The core idea for those builds is to build once with instrumentation, run the resulting instrumented binary against a profile, and rebuild with the data gathered from that. In our build system, this is what actually happens on Linux:
- Build everything with instrumentation.
- Run instrumented binary against profile.
- Remove half the object directory, including many non-compiled code things that are generated during a normal build.
- Rebuild with optimizations guided by the collected data.
Yes, the last step repeats things from the second that are not necessary to be repeated.
Second, Mac universal builds, which happen in the following manner:
- Build everything for i386.
- Build everything for x86-64.
- Merge the result of both builds.
Yes, "everything" in both "Build everything" includes the same non-compiled files. Then the third step checks that those non-compiled files actually match (and for buildconfig.html, has special treatment) and merges the i386 and x86-64 binaries in Mach-o fat binaries. Not only is this inefficient, but the code behind this is terrible, although it got better with the new packager code. And reproducing universal builds locally is not an easy task.
In the future, the build system would be able to compile binaries for different targets in a way that doesn't require jumping through hoops like the above. It could even allow to build e.g. a javascript shell for the build machine during a cross-compilation for Android without involving wrapper scripts to handle the situation.
Third party code
Building Firefox involves building several third party libraries. In some cases, they use gyp, and we convert their gyp files to moz.build at import time (angle, for instance). In other cases, they use gyp, and we just use those gyp files through moz.build rules, such that the gyp processing is done during configure instead of at import time (webrtc). In yet other cases, they use autoconf and automake, but we use a moz.build file to build them, while still running their configure script (freetype and jemalloc). In all those cases, the sources are handled as if they had been Mozilla code all along.
But in the case of NSPR, NSS and ICU, we don't necessarily build them in ways their respective build systems (were meant to) allow and rely on hacks around their build system to do our bidding. This is especially true for NSS (don't look at config/external/nss/Makefile.in if you care about your sanity). On top of using atrocious hacks, that makes the build dependable on Make for compilation, in inefficient ways, at that.
In the future, we wouldn't rely on NSPR, NSS and ICU build systems, and would build them as if they were Mozilla code, like the others. We need to find ways to allow that while limiting the cost of updates to new versions. This is especially true for ICU which is entirely third party. For NSPR and NSS, we have some kind of foothold. Although it is highly unlikely we can make them switch to moz.build (and in the current state of moz.build, being very tied to Gecko, not possible without possibly significant changes), we can probably come up with schemes that would allow to e.g. easily generate moz.build files from their Makefiles and/or manifests. I expect this to be somewhat manageable for NSS and NSPR. ICU is an entirely different story, sadly.
And more
There are many other aspects of the build system that I'm not mentioning here, but you'll excuse me as this post is already long enough (and took much longer to write than it really should).
2014-12-03 02:01:43+0900
You can leave a response, or trackback from your own site.

2014-12-03 11:56:47+0900
Hi,
did you consider using CMake ?
http://en.wikipedia.org/wiki/CMake
It replaces ./configure and produces a lot of different projects files like Makefiles, Visual studio project, Xcode project, Ninja… cf http://www.cmake.org/cmake/help/v3.1/manual/cmake-generators.7.html#cmake-generators
Best regards,
2014-12-03 13:39:48+0900
I’m not doing Gecko or C++ ATM, but found this very interesting still. All the things you have to take care of to make Firefox awesome and deliver it on all these platforms… wow.
Having someone on the team who cares about developer productivity is a real asset.
Your co-workers are lucky to have you on board!
2014-12-03 14:42:22+0900
This is very interesting, especially since I’m developing a build system myself (it’s called Meson, the link to it is on my name above).
The main slowdown of Make is recursive make. Have you considered moving to a single make process like e.g. LibreOffice currently does? Moving to Ninja should give an even bigger boost, as e.g. no-change Chromium builds on Windows take less than a second (IIRC).
Does your current build system use the shared library symbol trick that is at least in Meson, Chromium and Libreoffice does? That should cut down on incremental builds quite a lot.
Do you have multiplatform precompiled header support?