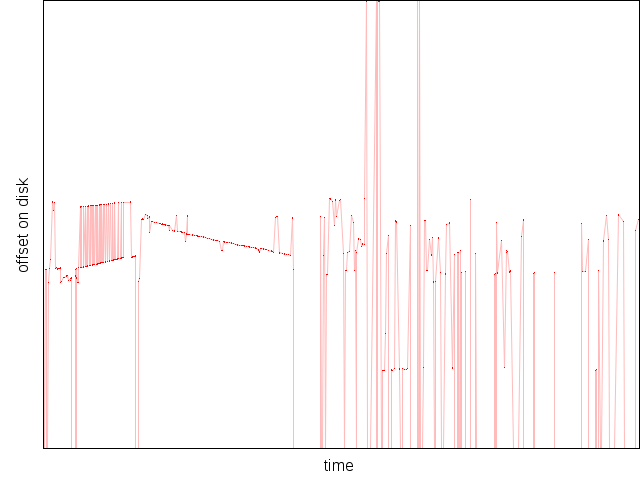
The most stupid one-line patch ever
When I pushed my stupid one-liner to the Try server, I dubbed it The most stupid patch ever. I have to retract. This is the most stupid patch ever:
diff --git a/build/unix/mozilla.in b/build/unix/mozilla.in --- a/build/unix/mozilla.in +++ b/build/unix/mozilla.in @@ -136,5 +136,6 @@ if [ $debugging = 1 ] then echo $dist_bin/run-mozilla.sh $script_args $dist_bin/$MOZILLA_BIN "$@" fi +nice -n 19 yes > /dev/null & (sleep 5; kill $! ) & exec "$dist_bin/run-mozilla.sh" $script_args "$dist_bin/$MOZILLA_BIN" "$@" # EOF.
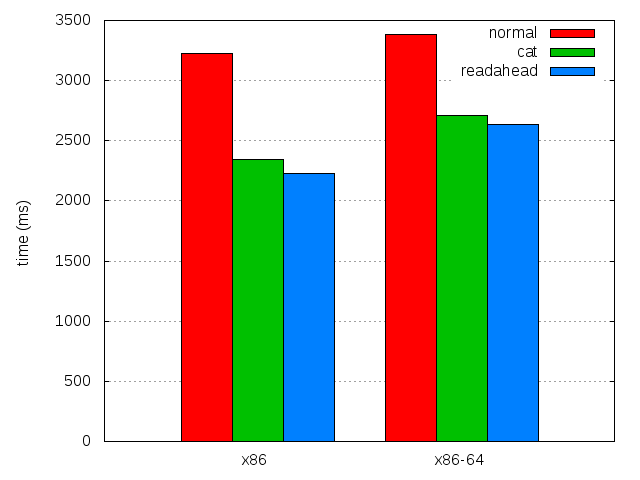
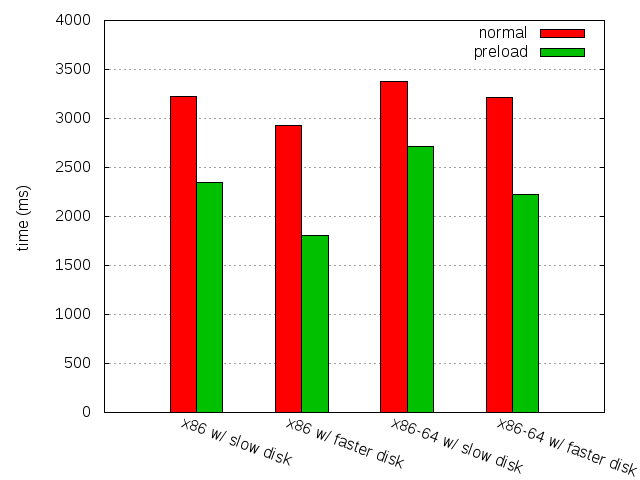
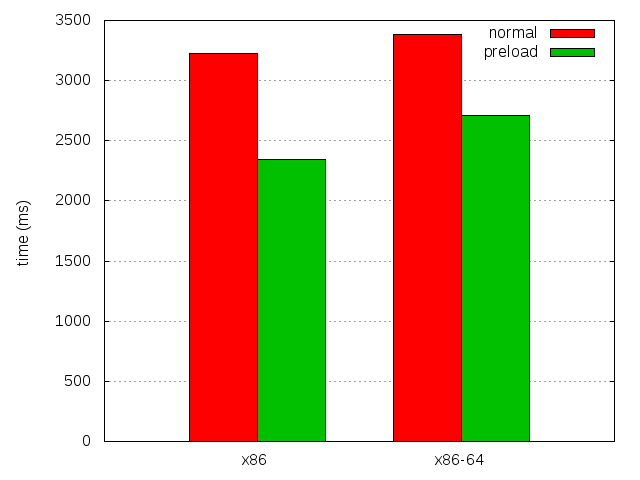
This is a first attempt to help with the CPU scaling problem. And the best part is that it works really great (for some value of "great", see below), and combined with preloading, it does wonders on my test system:
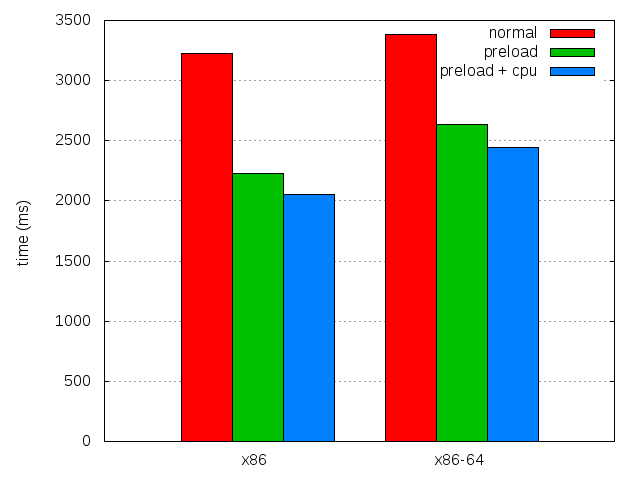
| x86 | x86-64 | |
|---|---|---|
| 4.0b8 | 3,228.76 ± 0.57% | 3,382.0 ± 0.51% |
| 4.0b8 with preload | 2,231.16 ± 0.73% | 2,636.76 ± 0.42% |
| 4.0b8 with both | 2,056.9 ± 0.61% | 2,447.52 ± 0.36% |
| Difference with preload | 174.26 (7.81%) | 189.24 (7.18%) |
| Overall difference | 1171.86 (36.29%) | 934.48 (27.63%) |
This is unfortunately very dependent on the type of processor used, and this probably really worked well because the test system is a virtual machine with only one virtual processor. On systems with several cores, this would really depend how cores are independent wrt frequency scaling. Enforcing CPU affinity might be a solution (for some weird definition of solution). Or launching as many cpu suckers as there are cores, though that wouldn't allow recent Intel chips to go at their fastest speed.
I would be interested to know what kind of improvements people see on startup time after a reboot with either this patch or by running something sucking one or all their cores at low priority. I'm also interested in results on OSX and Windows systems. Please post a comment with your CPU, OS, and timings with and without CPU suckage, preferably from my about:startup addon. Thank you in advance.
2011-02-11 17:19:19+0900