Analyzing shared cache on try
As mentioned in previous post, shared cache is now effective on try for linux and linux64, opt and debug builds, provided the push has changeset a62bde1d6efe in its history. The unknown in that equation was how long it takes for landings in mozilla-inbound or mozilla-central to propagate to try pushes.
So I took a period of about 8 days and observed, on a sliding 24-hours window, the percentage of pushes containing that changeset, and to see if the dev-tree-management post had an impact, I also looked at a random mozilla-central changeset, 339f0d450d46. This is what this looks like:
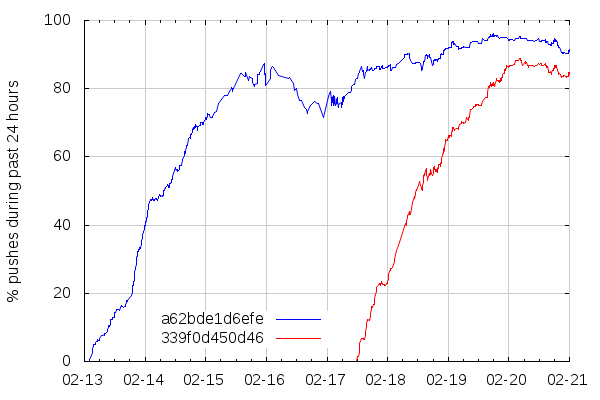
So it takes about 2 days and a half for a mozilla-central changeset to propagate to most try pushes, and it looks like my dev-tree-management post (which was cross-posted on dev-platform) didn't have an impact, although 339f0d450d46 is close enough to the announcement that it could still be benefitting from it. I'll revisit this with future unannounced changes.
The drop that can be seen on February 16 is due to there being less overall pushes over the week-end, and that somehow made pushes without changeset a62bde1d6efe more prominent. Maybe contributors pushing on the week-end are more likely to push old trees.
Now, let's see what effect shared cache had on try build times. I took about the last two weeks of successful try build logs for linux and linux64, opt and debug, and analyzed them to extract the following data:
- Where they were built (in-house vs AWS),
- Whether they were built with unified sources or not (this significantly changes build times),
- Whether they used the shared cache or not,
- Whether they are PGO builds or not,
- How long the "compile" step took (which, really, is "make -f client.mk", so this includes more than compilation, like configure and copying many files),
There sadly weren't enough PGO builds to plot anything about them, so I just excluded them. Then, since the shared cache is only enabled on AWS builds, and since AWS and in-house build times are so different, I excluded in-house builds. Further looking at the build times for linux opt, linux64 opt, linux debug and linux64 debug, they all looked similar enough that they didn't need to be split in different buckets.
Update: I should mention that I also excluded my own try pushes because I tended to do multiple rebuilds on them, with all of them getting near 100% cache hit and best build times.
Sorting all that data by build time, the following are graphs showing how many builds took less than a given build time.
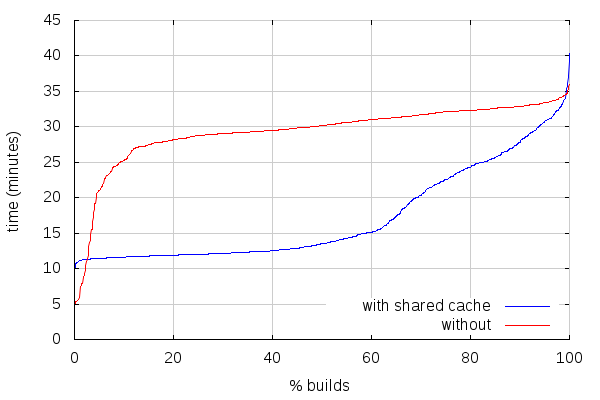
For unified sources builds (870 builds with ccache, 1111 builds with shared cache):
For non-unified sources builds (302 builds with ccache, 332 builds with shared cache):
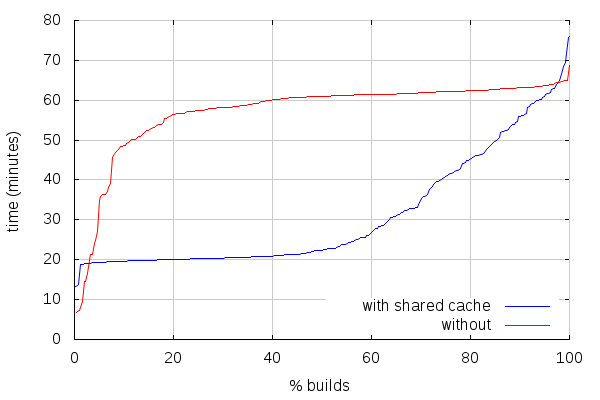
The first thing to note is that this does include the very first try pushes with shared cache, which probably skews the slowest builds. It should also be noted that linux debug builds are (still) currently non-unified by default for some reason.
With that being said, for unified sources builds, there are about 3.25% of the builds that end up slower with shared cache than with ccache, and 5.2% for non-unified builds. Most of that is on the best build times end, where builds with shared cache can spend twice the time we'd spend with ccache. I'm currently working on changes that should make the difference slimmer (more on that in a subsequent post). Anyways, that still leaves more than 90% builds faster with shared cache, and makes for a big improvement in build times on average:
| Unified | Non-unified | |||
|---|---|---|---|---|
| shared | ccache | shared | ccache | |
| Average | 17:11 | 29:19 | 30:58 | 57:08 |
| Median | 13:30 | 30:10 | 22:27 | 60:57 |
Interestingly, a few of the fastest non-unified builds with shared cache were significantly faster than the others, and it looks like what they have in common is that they were built on the US-East-1 region, instead of US-West-2 region. I haven't looked into more details as to why those particular builds were much faster.
2014-02-25 03:57:20+0900
Responses are currently closed, but you can trackback from your own site.

2014-02-25 04:56:01+0900
The speedup is because we deployed our new AWS spot bidding lib which allows us to bid on faster nodes when they are relatively cheap on the spot market. See https://bugzilla.mozilla.org/show_bug.cgi?id=974869
These are jobs that likely ran on m3.2xlarge nodes which are 2x faster than our usual mix of m3.xlarge and c3.xlarge(according to amazon specs).