Efficiency of incremental builds on inbound
Contrary to try, most other branches, like inbound, don't start builds from an empty tree. They start from the result of the previous build for the same branch on the same slave. But sometimes that doesn't work well, so we need to clobber (which means we remove the old build tree and start from scratch again). When that happens, we usually trigger a clobber on all subsequent builds for the branch. Or sometimes we just declare a slave too old and do a periodic clobber. Or sometimes a slave just doesn't have a previous build tree.
As I mentioned in the previous post about ccache efficiency, the fact that so many builds run on different slaves may hinder those incremental builds. Let's get numbers.
Taking the same sample of builds as before (spanning across 10 days after the holidays), I gathered some numbers for linux64 opt and macosx64 opt builds, based on the number of files ccache built: when starting from a previous build, ccache is not invoked as much (or so would we like), and that shows up in its stats.
The sample is 408 pushes, including a total of 1454 changesets. Of those pushes:
- 344 had a linux64 opt build, 2 of which were retriggered because of a failure, for a total of 346 builds
- 377 had a macosx64 opt build, 12 of which were retriggered because of a failure, and 6 more were retriggered for some other reason, for a total of 397 builds. This doesn't line up because 2 pushes had their build retriggered twice.
It's interesting to see how many builds we actually skip, most probably because of coalescing. I'd argue this is too many, but I haven't looked exactly how many of those are legitimate "no need to build this because it is android only" or similar patterns.
Armed with an AWS linux builder, I replayed those 408 pushes in an optimal setup: no clobber besides those requested by the build system itself, all pushes built on the same machine, in the order they land. I however didn't skip builds like the actual slaves do, but this really doesn't matter anyways since they are not building consecutive pushes anyways. Note configure was rerun for every push because of how my builder handles pulling from mercurial. We don't do that on build slaves but I'd argue we should, it would avoid plenty of build system level clobbers, and many "fun" build failures.
Of those 408 pushes, 6 requested a clobber at the build system level. But the numbers are very different on build slaves:
- On linux, out of 346 builds:
- 19 had a clobber by the build system
- 8 had a forced clobber (when using the clobberer)
- 1 had a periodic clobber
- 162 (!) had no previous build tree at all for whatever reason (purged previously, or new slave)
- for a total of 190 builds ending up starting with no previous build tree (54.9%)
- On mac, out of 397 builds:
- 23 had a clobber by the build system
- 31 had a forced clobber
- 34 had no previous build tree at all
- for a total of 88 builds with no previous build tree (22.2%)
(Note the difference in numbers of build system clobbers and forced clobbers is due to them being masked by the lack of previous build tree on linux)
Like for ccache efficiency, the use of a bigger build slave pool for linux builds is hurting and making them start from scratch more often than not, which doesn't help with the build turnaround times.
But even on the remaining non-clobber builds, if the source tree is significantly different, we may end up rebuilding as much as if we had clobbered in the first place. Sometimes it only takes a change to one file to do that (for example, add an AC_DEFINE in configure.in, and it will rebuild almost everything), but sometimes it can be an accumulation of changes. This is where the ccache stats get useful again.
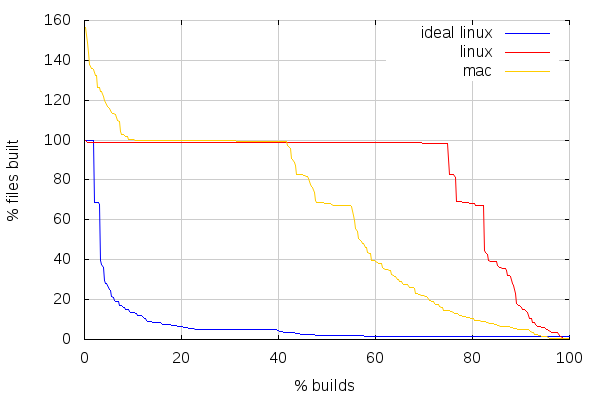
A few preliminary observations:
- There are always at least around 1.5% files rebuilt on ideal linux builds (which needs investigating), but a lot of the builds rebuilt around 5% because of bug 959519
- The number of source files can vary across pushes, but I used a more or less appropriate constant value for all builds, so some near 100% values may actually be 100%
- Mac builds surprisingly sometimes build the same files more than once. I filed bug 967976
The first thing to note on the above graph is that about 42% of mac builds and about 75% of linux builds are either clobbers or near-clobbers as I like to call them (incremental builds that just rebuild everything). Near-clobbers thus count for as many as 20% of overall builds on both platforms, or about 50% (!) of non-clobber builds on linux and about 25% of non-clobber builds on mac.
I can't stress enough how the build slave pool sizes are hurting our turnaround times.
It can be noted that there are a few plateaus around 82% and 69% files built, which are likely due to central headers being changed and triggering that many files to be rebuilt. This is the kind of thing that efforts like using include-what-you-use helps with, and we've made progress on that in the past months.
Overall, with our current setup, we are in a vicious circle. Adding more build types (like recently ASAN, Root analysis, Valgrind, etc.), or landing more stuff requires more slaves. More slaves makes builds slower for reasons given here and in previous posts. Slower builds require more slaves to keep up with landings. Rinse, repeat. We need to break the feedback loop.
(Fun fact: While I haven't been doing more than mercurial updates and building the tree to gather the ideal linux numbers (so no make package, no make check, etc.), it only took about a day. For 10 days worth of inbound pushes. With one machine)
2014-02-05 03:57:49+0900
Responses are currently closed, but you can trackback from your own site.

2014-02-05 05:36:03+0900
So it sounds like for a given amount of capacity, a smaller pool of faster builders would perform better than a larger pool of slower builders. Is this something we have any control over with AWS?
2014-02-05 07:49:11+0900
Unfortunately, faster builders don’t necessarily yield in much faster builds because there are many things that are not parallelized during builds. So the point is more that several smaller pools of the same builders would perform better than a global pool of those builders.