Iceweasel 5.0b2
... would have been released today if mozilla.debian.net was responding. But it's moving to a new server.
2011-05-21 08:17:50+0900
... would have been released today if mozilla.debian.net was responding. But it's moving to a new server.
2011-05-21 08:17:50+0900
Only amd64 and i386 packages are available. Note that there is another Iceweasel "version" available there: "aurora". Currently, this is the same as "5.0", but whenever Firefox 5.0 will reach the beta stage, "aurora" will be 6.0a2. Please feel free to use "aurora" if you want to keep using these pre-beta builds.
2011-05-02 19:00:42+0900
There are a lot of different workflows to maintain Debian packages under a Version Control System. Some people prefer to only keep the debian directory, some the whole source. And in the latter category, some prefer the source tree to be patched with Debian changes, while others prefer to keep it unpatched and exclusively use debian/patches.
It turns out the former and the latter don't work so well in one specific case that any package may hit some day ; and that day, you realize how wrong you were not tracking the entire patched source. That happened to me recently, though instead of actually going forward and switch to tracking the patched source, I cheated and simply ditched the patch, because I didn't strictly need it.
In all fairness, this is not only a case against not tracking patched source, but also a case of the 3.0 (quilt) source format being cumbersome.
In my specific case, I cherry picked an upstream patch modifying and adding some test cases related to a cherry-picked fix. One of the added test cases was a UTF-16 file. UTF-16 files can't be diff'ed nor patch'ed except in the git patch format, but quilt doesn't use nor support that. The solution around this limitation of 3.0 (quilt) format is to include the plain modified file in the Debian tarball, and add its path to debian/source/include-binaries.
On the VCS side of things, it means you have to modify the file in the source directory, and fill debian/source/include-binaries accordingly. Wait. Modify the file in the source directory ? But the other files aren't ! They're tracked by patches !
So here you are, with all of your modifications exclusively in debian/patches... except one.
2011-03-06 10:27:33+0900
I have been maintaining Debian Bug Tracking System graphs for a few years, now, though not very actively. They initially were available on people.debian.org/~glandium/bts/, but there have been some recent changes.
A while ago, I started experimenting with brand new graphs on merkel.debian.org/~glandium/bts/, and when merkel was announced to be dying a few months ago, I got in touch with the QA team to know what to do with them, and it was decided we'd put them on qa.debian.org. I unfortunately didn't follow up much on this and only recently actually worked on the migration, which took place 2 weeks ago.
The result is that the graphs have officially moved to qa.debian.org/data/bts/graphs/, and links on the Package Tracking System have been updated accordingly. There is now also an additional graph tracking all open bugs in the BTS, across all packages:

Today, I added a new feature, allowing to consolidate data for multiple arbitrary packages in a single graph. Such graphs can be generated with the following URL scheme (please don't over-abuse of it):
https://qa.debian.org/data/bts/graphs/multi/name0,name1,name2,etc.png
As an example, here is a graph for all the bugs on the packages I (co-)maintain:

And here are the bugs affecting Mozilla-related packages:

https://qa.debian.org/data/bts/graphs/multi/iceape,icedove,iceowl,iceweasel,nspr,nss,xulrunner.png
I guess the next step is to allow per-maintainer consolidation through URLs such as
https://qa.debian.org/data/bts/graphs/by-maint/address.png
Update: per-maintainer consolidation has been added.
(Hidden message here: please help triaging these bugs)
2011-03-05 14:21:31+0900
I'm glad that 5 years after the facts, people are still not getting them straight.
The Firefox logo was not under a free copyright license. Therefore, Debian was using the Firefox name with the "earth" logo (without the fox), which was and still is under a free copyright license. Then Mozilla didn't want the Firefox name associated to an icon that is not the Firefox icon, for trademark reasons. Fair enough.
Although at the time Debian had concerns with the trademark policy, there was no point arguing over it, since Debian was not going to use the logo under a non-free copyright license anyway.
Now, it happens that the logo has turned to a free copyright license. Request for a trademark license was filed a few weeks after we found out about the good news, and we are still waiting for an agreement draft from Mozilla to hopefully go forward.
It is still not certain that this will actually lead to Debian shipping something called Firefox some day, but things are progressing, even if at a rather slow pace, and I have good hope (discussions are promising).
By the way, thank you for the nice words, Daniel.
2011-02-07 20:42:47+0900
最近ã®Iceweaselベータã§ãƒ¡ãƒ‹ãƒ¥ãƒ¼ãƒãƒ¼ã‚’éš ã—ã¦ã€ãã®ä»£ã‚ã‚Šã«IceweaselボタンãŒè¡¨ç¤ºã•ã‚Œã¾ã™ã€‚ãã†ã™ã‚‹ã«ã¯ãƒ¡ãƒ‹ãƒ¥ãƒ¼ãƒãƒ¼ã«å³ã‚¯ãƒªãƒƒã‚¯ã—ã¦ã€ãƒ¡ãƒ‹ãƒ¥ãƒ¼ãƒãƒ¼ã‚’無効ã«ã—ãŸã‚‰IceweaselボタンãŒç¾ã‚Œã¾ã™ã€‚
ã‚ã¾ã‚Šé…力的ã§ã¯ã‚ã‚Šã¾ã›ã‚“ã—ã€ã‚¿ãƒ–ãƒãƒ¼ã®å ´æ‰€ã‚’無駄ã«å–ã‚Šã¾ã™ãŒã€å°‘ã—ã®CSSã§å¤‰ãˆã‚‰ã‚Œã¾ã™ã€‚ユーザーã®ãƒ—ãƒãƒ•ã‚¡ã‚¤ãƒ«ã®chrome/userChrome.cssã«ä¸‹è¨˜ã®CSSã‚’è¿½åŠ ã—ã¦ä¸‹ã•ã„:
#appmenu-toolbar-button {
list-style-image: url("chrome://branding/content/icon16.png");
}
#appmenu-toolbar-button > .toolbarbutton-text,
#appmenu-toolbar-button > .toolbarbutton-menu-dropmarker {
display: none !important;
}
ãã‚Œã§ã€Iceweaselã¯ã“ã†ãªã‚Šã¾ã™ï¼š
![]()
2011-01-15 16:22:43+0900
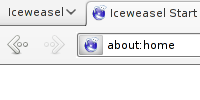
Recent Iceweasel betas allows to replace the menu bar with a Iceweasel button. This is not enabled by default, but right-clicking on the menu bar allows to disable the menu bar, which enables the Iceweasel button.
The button is not exactly very appealing, and takes quite a lot of horizontal space on the tab bar. But with a few lines of CSS, this can fortunately be changed. Edit the chrome/userChrome.css file under your user profile, and add the following lines:
#appmenu-toolbar-button {
list-style-image: url("chrome://branding/content/icon16.png");
}
#appmenu-toolbar-button > .toolbarbutton-text,
#appmenu-toolbar-button > .toolbarbutton-menu-dropmarker {
display: none !important;
}
This what Iceweasel looks like, then:
![]()
2011-01-15 15:49:20+0900
ãŠä¹…ã—ã¶ã‚Šã§ã™ã€‚
Debianアーカイブã§ã¾ã é…布出æ¥ãªã„パッケージã®é…布ã®ä»•æ–¹ã‚’変化ã•ã›ã¦ã„ãŸã ãã¾ã—ãŸã€‚ã“ã‚Œã‹ã‚‰ã¯4.0ベータを利用ã™ã‚‹ã«ã¯ä¸‹è¨˜ã®APTã®ã‚½ãƒ¼ã‚¹ã‚’è¿½åŠ ã—ã¦ãã ã•ã„:
deb http://mozilla.debian.net/ experimental iceweasel-4.0
Experimentalã®ãƒªãƒã‚¸ãƒˆãƒªã‚‚å¿…è¦ã§ã™ã®ã§ã€APTã®sources.listã«è¿½åŠ ã—ã¦ãã ã•ã„。ãã®è¨å®šã§4.0ベータã®ã‚¤ãƒ³ã‚¹ãƒˆãƒ¼ãƒ«ãŒä¸‹è¨˜ã®é€šã‚Šã«ç°¡å˜ãªã¯ãšã§ã™ï¼š
# apt-get install -t experimental iceweasel
Squeezeã§ã‚‚unstableã§ã‚‚利用出æ¥ã‚‹ã¯ãšã§ã™ã€‚
Debian Lennyå‘ã‘ã®Iceweasel 3.6ã®backportã‚‚é…布ã—ã¾ã™ã€‚インストールã™ã‚‹ã«ã¯ä¸‹è¨˜ã®APTã®ã‚½ãƒ¼ã‚¹ã‚’è¿½åŠ ã—ã¦ãã ã•ã„:
deb http://mozilla.debian.net/ lenny-backports iceweasel-3.6
Lenny-backportsã®ãƒªãƒã‚¸ãƒˆãƒªã‚‚å¿…è¦ã§ã™ã®ã§ã€APTã®sources.listã«è¿½åŠ ã—ã¦ãã ã•ã„。Experimentalã®ã‚ˆã†ã«ã‚¤ãƒ³ã‚¹ãƒˆãƒ¼ãƒ«ãŒä¸‹è¨˜ã®é€šã‚Šã«ç°¡å˜ãªã¯ãšã§ã™ï¼š
# apt-get install -t lenny-backports iceweasel
APTãŒå…¬é–‹éµã‚’利用出æ¥ãªã„å ´åˆã¯å…¬é–‹éµã‚’APTã‚ーリングã«è¿½åŠ ã™ã‚‹èª¬æ˜Žã‚’èªã‚“ã§ã¿ã¦ãã ã•ã„(英語)。
2011-01-14 17:36:41+0900
I made some changes as to how packages from the Debian Mozilla team that can't yet be distributed in the Debian archives are distributed to users. Please update your APT sources and now use the following for 4.0 beta packages:
deb http://mozilla.debian.net/ experimental iceweasel-4.0
You'll also need the experimental repository in your sources, but the overall installation is much easier now:
# apt-get install -t experimental iceweasel
This should work for squeeze and unstable users.
I also added Iceweasel 3.6 backports for Debian Lenny users. For these, add the following APT source:
deb http://mozilla.debian.net/ lenny-backports iceweasel-3.6
You'll also need the lenny-backports repository in your sources. As for the experimental packages above, installation should be as easy as:
# apt-get install -t lenny-backports iceweasel
If your APT complains about the archive key, please check the instructions to add the key to your APT keyring.
2011-01-14 10:25:48+0900
 The contents of this site are licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. Comments copyrights belong to their respective authors.
The contents of this site are licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License. Comments copyrights belong to their respective authors.